
Good Heavens, Gods?
Hell No, Dogs!
Juha Meskanen
Universal Edition
This is a private draft!
Build:
Please review the latest available release at https://meskanen.com/abstract/ghd.pdf.
If you find an error or feel compelled to provide feedback, please do so. All critical yet constructive feedback is highly appreciated!
All opinions expressed are my own and do not reflect the views of any other person or organization.
This book applies software design methods to gods, which some readers may find inappropriate. All references to deities are made in good faith, with no intention of offending anyone’s beliefs. If this content conflicts with your convictions, please return the book for a full refund.
The abbreviation of this book, GHG, should not be confused with Greenhouse Gas.
No animals were harmed in the creation of this book.
In no event shall the author be liable for any damages, including, but not limited to, psychological distress, unhandled existential exceptions, or an intense, sudden urge to explain thermodynamics at dinner parties.
Draft Edition
Copyright 2001–2025 Juha Meskanen
All rights reserved.
This page tracks significant changes across the various draft releases.
First public draft containing the core material.
Added the \(E=mc^2\) example to Chapter to provide a minimal illustration of the problems that arise when attempting to model “reality”.
Added chapter about quantum-cosmology: .
Improved typesetting, internal cross-referencing, and overall LaTeX document structure.
Thought experiments in the chapter completed with exact definitions of Bolzzman entropy and references look Page-Footters (Page and Wootters 1983).
[Anyone?]
The spark that ignited this project was not a sudden flash of inspiration, but a painful personal accident. My highly respected dentist recommended the precautionary removal of a wisdom tooth. “Problems might appear later,” he warned, “and they will only get worse with time.”
Trusting his expertise, I followed his advice. Soon I was one tooth—and a few hundred dollars—lighter. Unfortunately, the problems only worsened. The socket refused to heal, leaving the nerves exposed. With Christmas holidays in full swing, all dentists were off duty. For several days, the pain expanded from one tooth until it felt as though my entire head was aching.
I did not handle the pain gracefully. First, I blamed the sugar industry for ruining people’s teeth with such a toxic product. Next came my dentist. Before long, I was even accusing the government education system of failing to train competent professionals.
Eventually the holidays ended, the clinic reopened, and the issue was finally resolved. Relief came quickly. Yet what remained long after the pain subsided was a question I had discussed many times with my colleagues: Can pain ever be implemented as software?
My colleague, apparently blessed with better teeth, believed it was possible. With the right sensors, firmware, and code, a robot could be made to simulate agony. I strongly disagreed. To behave as if in pain, I argued, is not the same as feeling pain. I could not see how genuine pain could ever be implemented in a programming language.
It was this missing “pain function” in the standard library of C that planted the seed of an obsession—an obsession that has grown, over years of thought and trial and error, into the work you are now reading.
The conclusions presented in this book were developed using the same software design methods and tools I have relied on throughout my career as a software professional. The software I have built with these methods works reliably. Accordingly, I believe the conclusions developed with them should hold as well.
However, no program is without bugs, and no complex argument is without potential flaws. Some parts of the reasoning presented here may contain errors. Still, I am confident that, as with well-designed software, these imperfections will not obscure the larger picture.
I owe my deepest gratitude to my wife. She is quite a remarkable piece of work—far more complex than anything found in the standard library of C. She patiently endured countless late nights listening to the clicking of my noisy laptop. Despite the many disruptions to her sleep, she remained remarkably understanding and supportive throughout the writing of this book.
I also owe a great debt to my brother, along with an apology for the many fishing trips I surely spoiled by relentlessly subjecting him to my theories.
Special thanks—or perhaps playful blame—go to Andy Jones. His gift of the book The Structure of Space and Time proved truly transformative. Without that “gift,” I might never have developed the necessary obsession to bring this work to completion.
Finally, I wish to honor the memory of my dog, Raju (R.I.P.), my loyal hunting companion, with whom I shared so many memorable hunts—and to the hares, R.I.P. as well.
During the past centuries, physics has achieved remarkable success in unifying a large number of partial theories into two powerful frameworks: Quantum Mechanics (QM) and General Relativity (GM). The equations in both theories match all observations with remarkable precision, limited only by current technological capabilities. Those capabilities themselves have reached a level that would have seemed almost inconceivable only a few decades ago.
Space-based observatories such as the James Webb Space Telescope now directly image the early universe, resolving infrared signals emitted only a few hundred million years after the Big Bang. Its operation depends simultaneously on quantum optics, relativistic orbital mechanics, and nanometer-scale wavefront control, turning cosmological theory itself into an engineering requirement.
At the opposite extreme, global interferometric arrays such as the Event Horizon Telescope resolve horizon-scale structure around black holes, directly probing the geometry of spacetime in the strong-field regime predicted by general relativity.
Gravitational-wave observatories such as LIGO can detect distortions of spacetime smaller than a proton’s diameter, measuring relative changes in length caused by distant black-hole mergers billions of light-years away. To put that into perspective, if one were measuring the distance to the nearest star (Proxima Centauri, about 4.2 light-years away), LIGO’s sensitivity would be equivalent to measuring that distance to within the width of a human hair.
Atomic clocks, exploiting the quantum structure of atoms, now keep time so precisely that they would lose or gain less than a second over the age of the universe, and are sensitive enough to register differences in gravitational potential corresponding to changes in height of mere centimeters.
Elsewhere, quantum electrodynamics predicts the magnetic moment of the electron to a precision verified to many decimal places, making it one of the most accurately tested theories in all of science. Interferometers routinely resolve wavelengths far smaller than the structures they probe, while particle accelerators recreate conditions not seen since the earliest moments after the Big Bang.
Comparable advances span quantum control experiments (Bose–Einstein condensates and quantum simulators), neutrino observatories (IceCube, Super-Kamiokande), and precision cosmology (Planck, ACT, SPT).
The theoretical descriptions of nature have become so accurate that reality itself now serves as the experimental apparatus for testing them. Physical law is no longer merely inferred from observation; it is continuously confirmed, corrected, and operationalized by technologies that depend on its validity to function at all. The theories have escaped the confines of paper and chalk and become embedded in the technological fabric of modern civilization. An obvious example is computation. From the quantum-mechanical behavior of transistors to the relativistic corrections required for satellite navigation, our deepest physical theories now operate continuously and invisibly inside machines that process information at planetary scale. Computation is no longer merely a tool for studying nature; it has become a physical process in its own right, governed by energy constraints, thermodynamics, noise, and quantum limits.
This trajectory has culminated in the rise of artificial intelligence systems of unprecedented complexity. These systems are not programmed in the traditional sense but are shaped through optimization processes that resemble physical evolution more than logical deduction. Trained on vast datasets and executed on hardware operating near fundamental physical limits, they exhibit behaviors—learning, abstraction, and generalization—that were once considered exclusively biological. Remarkably, their success does not rely on new physical laws, but on exploiting known ones at scale, transforming raw energy into structured information with extraordinary efficiency.
While many of the most sophisticated scientific instruments ever built serve no immediate practical purpose beyond testing fundamental laws of nature, science has also been remarkably productive in more everyday domains. Smartphones, global navigation systems, not to mention AI-enhanced electric toothbrushes and nuclear weapons now permeate daily life.
Science has much to celebrate.
Given the extraordinary convergence between theory, experiment, and technology in modern physics, one might expect that the final unification of physical law is close at hand. After the successful consolidation of earlier partial theories into the two great pillars of modern physics—General Relativity and Quantum Mechanics—it seemed almost inevitable that the process would culminate in the ultimate goal of physics: a Theory of Everything, a single equation describing the entire universe. Yet this expectation has not been realized. Despite overwhelming empirical support for both frameworks, their current formulations remain fundamentally incompatible. And while empirical disagreement may signal the need for refinement, mathematical inconsistency is decisive: a theory that is internally inconsistent cannot be a fundamental description of nature.
Historically, most attempts at unification assume that the quantum description is more fundamental, so it is General Relativity that should be modified, because everything else has already been quantized. Matter fields—electrons, photons, quarks—all obey quantum field theory. Spacetime might simply be another field awaiting quantization, and several facts appear to support this view.
First, GR breaks down at small scales. Near singularities or at the Planck length, curvature appear to become infinite. This signals a failure of the continuum picture, not of quantum mechanics. The intuition is therefore to quantize gravity to remove these divergences, just as quantizing electromagnetism resolved the ultraviolet catastrophe.
However, despite decades of research, no single framework has yet succeeded in combining the principles of quantum mechanics with the geometric description of spacetime provided by General Relativity. Attempts at unification, e.g. string theory, have become so intricate that the complexity itself now poses the greatest challenge. In effect, we have constructed a rock too heavy even for its creators to lift.
In addition to the well-known difficulty of constructing a unified Theory of Everything, there is a deeper and arguably more serious problem: all candidate theories rely on unexplained assumptions.
General Relativity posits that spacetime exists as a smooth, differentiable manifold equipped with a metric tensor whose curvature is determined by the Einstein field equations. The theory describes with extraordinary precision how spacetime bends in the presence of energy and momentum. Yet it remains silent on what spacetime is in itself. Is it a physical substance, an emergent phenomenon, a relational structure among events, or merely a mathematical framework? What, if anything, is it made of? Why does it have four macroscopic dimensions? Why does it possess the specific Lorentzian signature it does? There are two fundamental constants that enter the theory and are not derived from it: the gravitational constant coverning the strength of gravity, and the cosmological constant acting like uniform energy density filling space. What sets the values for these constants?
Quantum Field Theory is even worse. It assumes the existence of quantum fields defined over spacetime. Each type of particle corresponds to excitations of an underlying field. However, the theory presupposes the prior existence of these fields, their commutation relations, their gauge symmetries, and a substantial number of experimentally determined parameters: coupling constants, particle masses, mixing angles, and the structure of the gauge group. The Standard Model works with remarkable accuracy, yet it does not explain why these particular fields exist, why the symmetry group has its specific form, or why the constants take the values they do.
String Theory attempts to move deeper by replacing point particles with one-dimensional strings and by incorporating gravity in a quantum framework. Yet it assumes additional compactified spatial dimensions, specific consistency conditions, and a vast landscape of possible vacuum states—each corresponding to different low-energy physics. The theory shifts the explanatory burden but does not eliminate it: why this vacuum rather than another? Why this compactification geometry? Why strings at all?
In each case, the formalism specifies dynamical laws operating on pre-existing structures. What remains unexplained are the origins and necessity of those structures themselves.
This incompleteness can be expressed schematically as:
\[\text{ToE}_{\text{incomplete}} = \text{ToE}_{\text{complete}} \setminus \mathcal{A},\]
where \(\mathcal{A}\) denotes the set of fundamental assumptions left unexplained.
What kind of theory of everything is a theory that is not, in fact, about everything?
Furthermore, should the ultimate goal of physics be not only to predict what happens in the universe, but also to help us understand what reality truly is? What is fundamentally taking place?
Physical theories must ultimately be tested against observation. Without falsifiable consequences, a framework belongs more to philosophy than to physics.
Most mainstream physical theories treat the observer as external, presupposing that the universe exists independently of anyone observing it. Yet observation and experience are the only means by which the universe is tested and theories are verified. Every empirical statement rests on perception, measurement, memory, and inference.
Since the early development of quantum mechanics, the role of the observer has been a source of persistent unease. Einstein famously objected to interpretations that appeared to grant observation a fundamental role, asking whether the Moon would cease to exist when no one looked at it. Bohr, by contrast, argued that physics is not a description of nature as it is in itself, but a framework for organizing what can be said about observations.
Nearly a century later, this tension remains unresolved. Most physical theories are still formulated as if observers were external to the universe they describe, even though observers are themselves physical systems embedded within that universe. The formalism typically specifies states, fields, and dynamical laws, yet leaves the observer undefined.
If a Theory of Everything aspires to completeness, shouldn’t it explain everything—including the existence, structure, and role of observers?
Even if physics achieves its goal of unifying General Relativity and Quantum Mechanics into a single theory of quantum gravity, will it ever be able to explain the nature of consciousness—such as the experience of pain—and reach the ultimate goal: a true ’Theory of Everything’?
None of our current physical theories include equations for human experience. Pain does not contribute to Einstein’s stress-energy tensor, and there is no particle carrying consciousness in the Standard Model of particle physics. What, then, is the source of consciousness and our capacity for sensation—the raw reality of a toothache?
Will science and physics ever be capable of answering these profound questions, or must we seek the answers elsewhere?
The holy grail of theoretical physics and cosmology has always been to find a singular, self-evident first principle from which all of reality can be derived. Our intuition seems to demand a framework that does not smuggle in arbitrary starting conditions.
We are dissatisfied with the Standard Model of particle physics precisely because it forces us to accept, without explanation, at least 19 free parameters: fine-tuned constants such as the fine-structure constant \(\alpha\), the gravitational constant \(G\), and the masses of various particles. To a philosophically minded software developer, accepting these numbers as "just because" feels like intellectual surrender.
And software developers are apparently not the only ones dissatisfied with mainstream physics. Several theories seek to derive the laws of physics from minimal assumptions.
Ludwig Boltzmann proposed that in a system at thermal equilibrium (maximum entropy), rare fluctuations can temporarily produce ordered structures. In such a framework, sufficiently complex configurations—including observers—can arise given enough time.
Max Tegmark’s Mathematical Universe Hypothesis is another rival. It posits that all mathematically consistent structures physically exist, requiring no external creator or physical spark.
A third major candidate is Archibald Wheeler’s "It from Bit" paradigm, where physical reality is derived entirely from the binary processing of quantum information.
However, none of these theories are truly presumptionless. Bolzmannn assumes time and dynamics. Tegmark assumes that mathematical structures exist as a fundamental substrate, and ’It from Bit’ takes the validity of quantum mechanics for granted. In all cases, the ’minimal’ starting point is actually quite a lot to assume.
The fundamental trouble with these lawless, ultimate first-principle theories is also that they do not yield the universe we actually observe. They struggle to get even two planets to orbit each other with inertia, let alone derive the smooth, continuous spacetime metric.
It would actually make sense to assume that reality is born from pure probabilistic fluctuations in an infinite sea of chaos. It would then be something we could truly understand. However, we immediately run into the Boltzmann Brain paradox. In a truly random infinity, it is statistically far more probable for a single conscious brain with false memories to fluctuate into existence than a vast, ordered universe governed by rigid laws.
If the universe is based on mathematics, we are immediately plagued by the measure problem. There are infinitely more chaotic, non-computable, and glitchy mathematical structures than there are simple, elegant ones. Without adding an external, ad-hoc rule favoring simplicity, this theory predicts we should live in a wildly unstable, incomprehensible reality.
Algorithmic Information Theory is an exceptional tool for ledger-keeping and measuring quantum states, but it fails to natively explain why mass resists acceleration (inertia) or how smooth, continuous gravity emerges from discrete bits.
The failure of these theories to produce working physics may point toward a deeper, more uncomfortable truth about the nature of reality and logic itself.
To state that we must start by assuming absolutely nothing is, in itself, an assumption. This is one of those ultimate manifestations of Gödel’s Incompleteness Theorem. At bare minimum, there must be at least one foundational premise. And if a system requires at least one assumption to exist, then what is it that dictates that there must be only one? Why not two? Why not nineteen?
The nineteen seemingly arbitrary constants of the Standard Model, the specific geometry of quantum Hilbert spaces, and the non-negotiable rules of General Relativity may just be the irreducible brute facts required to have this universe at all.
Reductionism apparently has a floor. We can reduce chemistry to physics, and physics to quantum fields, but we may eventually hit a bedrock of arbitrary, predefined constants that cannot be derived from anything deeper.
Just as the large number of pre-assumptions in our major theories feels unsatisfactory, it also seems problematic that we rely on two separate, partial frameworks—General Relativity (GR) and Quantum Mechanics (QM)—to describe a single universe.
Both GR and QM work spectacularly well within their respective domains. However, the moment we attempt to merge them into a unified theory of quantum gravity, this success comes to a screeching halt.
When we combine the smooth, continuous geometry of spacetime with the inherently probabilistic machinery of quantum mechanics, the equations do not merely break down—they do so dramatically, producing infinities and physically meaningless results.
One of the earliest attempts to bridge the quantum–classical divide is semiclassical gravity. In this approach, matter is treated as fully quantum, while spacetime remains classical. To make the Einstein field equations workable, the operator-valued stress–energy tensor of quantum matter is replaced by its expectation value—the renormalized average of the energy and momentum calculated over the quantum state of the matter fields. This resulting set of ordinary numbers can then be inserted into the equations governing curvature.
Semiclassical gravity is remarkably successful. It accurately describes a wide range of phenomena, from laboratory experiments to astrophysical observations and cosmology. It even predicts striking effects such as Hawking radiation in black holes. Yet its very success also exposes its conceptual limitation: the approach is ad hoc. The theory works well for everything we can observe, but it does not answer any of the deeper question, like what is the physics at the singularity of a black hole.
A natural next step is perturbative quantum gravity, where spacetime is expanded around a simple background—typically flat or slightly curved—and the perturbations are treated as quantum fields. This approach is conceptually straightforward and extends the familiar machinery of quantum field theory to gravity.
However, it quickly runs into a fundamental problem: gravity is nonrenormalizable. Unlike the Standard Model, where quantum infinities can be systematically controlled, perturbative gravity’s divergences become increasingly severe at higher energies. To cancel these, we are forced to introduce new counterterms at every order of the calculation. This process never terminates, requiring an infinite number of independent parameters to be measured and fixed. Ultimately, this strips the theory of its predictive power; instead of a concise model, we are left with an infinite list of unknowns. The techniques that work spectacularly well for matter fields simply break down for spacetime itself.
In response to the failure of perturbative quantization, researchers have developed nonperturbative frameworks that do not assume a fixed background geometry. These include Loop Quantum Gravity (LQG), Causal Dynamical Triangulations, Asymptotic Safety, Causal Set Theory and Noncommutative Geometry (NCG). While all these represent valuable research programs, they all remain incomplete as full theories of quantum gravity.
A leading example is Loop Quantum Gravity (LQG), which models spacetime as a discrete combinatorial structure of spin networks. LQG is mathematically rigorous and fully background-independent, offering a conceptually clean quantization of geometry.
The theory is a cousin to Penrose’s Twistor program in that his work on spinors and spin networks provided the mathematical toolbox that allowed LQG to exist.
However, it seems major obstacles still remain. Deriving a smooth classical spacetime limit is nontrivial, and embedding standard particle physics into the LQG framework remains unresolved. Despite its mathematical rigor and background independence, LQG faces persistent challenges in recovering a realistic low-energy limit. The emergence of a smooth, 4-dimensional classical spacetime with the correct long-distance dynamics (including the Einstein equations) is not fully under control, often relying on semiclassical approximations or specific choices of states. Incorporating matter fields, particularly chiral fermions from the Standard Model, encounters issues like fermion doubling or difficulties in coupling them consistently without breaking key symmetries. Lorentz invariance violations predicted in some early formulations have not been observed experimentally, forcing adjustments that weaken distinctive predictions. Overall, while it quantizes geometry cleanly, it has not yet produced a complete, predictive quantum theory of gravity unified with particle physics.
A conceptually direct attempt to quantize gravity involves applying canonical quantization to General Relativity. In this approach, 4D spacetime is decomposed into a foliation of spatial slices (the 3+1 formalism), allowing the Einstein equations to be rewritten in Hamiltonian form, for compatibility with Quantum Mechanics.
Upon quantization, the classical constraints of General Relativity are promoted to operator equations acting on a wavefunction, which encodes the quantum state of the spatial geometry. The central result is the Wheeler-DeWitt equation:
\[\hat{H}\Psi[h_{ij}] = 0.\]
The irony is that while trying to make General Relativity compatible with Schrödinger equation, the resulting equation actually lacks the time derivative essential in the Schrödinger equation. By trying to force GR into the "Hamiltonian" box of QM, the time variable disappears entirely.
This leads to the "Problem of Time": whereas standard quantum mechanics describes states evolving against a background time, the wavefunction of the universe appears static. Recovering time as an emergent or relational concept remains a profound open problem.
Despite this, Stephen Hawking’s Euclidean Quantum Gravity program utilized the Wheeler-DeWitt framework alongside Wick rotations and path integrals to define the "No-Boundary" proposal.
In string theory, the traditional concept of zero-dimensional point particles is replaced by one-dimensional strings. The vibrational frequency of a string determines the mass and charge of a particle, much like different notes played on a guitar string.
The theory’s primary selling point is its inherent ability to unify gravity with the standard model of particle physics. Gravity emerges naturally as one of the vibrational modes of the string—specifically the massless, spin-2 graviton. Beyond this, the framework encompasses deep mathematical structures such as dualities, extra dimensions, and black-hole entropy counting.
The earliest framework, bosonic string theory, is mathematically consistent only in 26 spacetime dimensions. Later, the introduction of supersymmetry led to superstring theories, which include fermionic degrees of freedom and are consistent in 10 dimensions. These dimensions are not arbitrary; consistency requires the cancellation of quantum anomalies on the string worldsheet. From a mathematical perspective, these constraints represent a form of elegance: the structure of the theory tightly restricts the space of consistent possibilities.
However, several open issues prevent string theory from being accepted as a complete physical theory.
First, most formulations are not manifestly background independent. It is a candidate of ToE, except the spacetime geomeotry, which it doesn’t explain but pre-assumes. If a theory starts with a stage already built, someone is entitled to ask who hired the carpenter.
This stands in contrast to general relativity, where spacetime geometry is fully dynamical and not a fixed stage.
Second, the theory relies on supersymmetry (SUSY), which predicts that every known particle has a “superpartner” with a spin differing by \(1/2\). Despite the high energy reach of modern colliders, none of these predicted sparticles have been detected.
Third, the theory admits an enormous landscape of possible vacuum states, estimated at \(10^{500}\). Our universe would correspond to the one that happens to produce the physics we observe. These vacua arise from the myriad ways of compactifying the extra dimensions into complex shapes known as Calabi-Yau manifolds. The specific geometry of these manifolds, combined with the way higher-dimensional objects called “branes” wrap around them, dictates the physics of the resulting 4D universe. This raises significant concerns regarding predictivity and falsifiability; if the theory can accommodate almost any physics, it may lack the power to uniquely predict our own.
Despite these challenges, string theory remains a dominant tool for theoretical discovery. One of its most significant modern pillars is the AdS/CFT correspondence. This duality relates a theory of gravity in a specific volume (Anti-de Sitter space) to a quantum field theory on its boundary. This “holographic principle” has allowed physicists to use the mathematics of string theory to solve problems in nuclear physics and condensed matter, even in the absence of direct experimental evidence for strings themselves.
The long-term ambition remains a unified, possibly background-independent framework. In 1995, Edward Witten proposed that the five consistent superstring theories are different limits of a deeper, 11-dimensional framework known as M-theory. While M-theory introduced branes and suggested that an additional spatial dimension emerges at strong coupling, it remains an incomplete framework. We currently lack a non-perturbative master principle—a definitive “M-theory action”—that would serve as the theory’s starting point.
Ultimately, direct experimental tests of string-scale physics remain out of reach. While the theory’s flexibility allows it to accommodate reality, the mechanism required to derive our specific universe from first principles remains undiscovered. In this sense, string theory remains a monumental mathematical achievement that has yet to prove its physical inevitability.
A more radical class of ideas treats gravity and spacetime as emergent rather than fundamental. This perspective arose from puzzles at the intersection of gravity, thermodynamics, and quantum theory. Black holes behave as thermodynamic objects, possessing entropy proportional to horizon area and emitting thermal radiation. These results suggest a deep link between geometry, information, and statistical mechanics.
The observation that gravitational entropy scales with area rather than volume led to the holographic principle: the idea that the degrees of freedom of a region of spacetime may be encoded on its boundary. Holographic dualities further support this view, showing that spacetime geometry and gravitational dynamics can emerge from nongravitational quantum theories.
The holographic principle argues that a three-dimensional universe can be described by a two-dimensional theory (\(N \rightarrow N-1\)). This is actually quite surprising result. Everything that happens in the universe (whether it had four dimensions or eleveven, can be described by its \(N-1\) dimensional surface.
During recent years so-called Simulation Hypothesis has become increasingly popular. If \(3D\) can map to \(2D\), why stop there? In software architecture, any \(N\)-dimensional space is ultimately stored as a one-dimensional bitstring (\(N \rightarrow 1\)). A sequence of bits has no intrinsic geometry, it is just a set of information.
If the universe is fundamentally informational, it is tempting to conclude that we are merely a program running on some higher-order "hardware." In this view, the strange "quantization" of our world is simply the resolution of the grid, and the speed of light is the clock-speed of the processor.
However, the simulation hypothesis feels like a philosophical "shell game." It merely translates the mystery of existence by one level: if we are a simulation, who simulated the simulators? Furthermore, it ignores the staggering Information Cost of reality.
Consider the entropy of a single human being. To simulate even a single strand of DNA with perfect fidelity requires tracking billions of quantum interactions. To harvest enough information from a "parent universe" to simulate an entire "child universe" would require a massive thermodynamic overhead. To simulate a universe would require a computer larger than the universe itself. Even if the simulation used ’lazy loading’—only rendering the parts of reality that are currently being observed, who would pay the electricity bill for that project?
From a developer’s perspective: The simulation hypothesis might explain why General Relativity and Quantum Mechanics appear so difficult to unify. Anyone familiar with software engineering understands the reality of legacy code. The fundamental incompatibility between the smooth, geometric curves of General Relativity and the discrete, probabilistic jumps of Quantum Mechanics might not be a profound mystery of nature, but simply a case of poor design. In this light, the universe is a patchwork of modules written by incompetent architects, at different times, with different goals.
It is easy to imagine a powerful computer with a huge database and advanced logic. Such a system could be highly efficient in its operations, capable of making accurate and intelligent decisions in nearly any imaginable situation. However, it is difficult to see how such a mechanically operating machine could truly feel pain.
Imagine a typical software program consisting of thousands of lines
of code. How many additional source lines would need to be added to
transform the software into a conscious entity? Would it be the \(10^{14}\)th line that suddenly imbues the
system with the ability to feel pain? Could it be the introduction of a
deeply nested loop that finally grants consciousness? Or is it the
number of if-else clauses that holds the secret?
Regardless of the number of loops and source lines added, it appears that nothing significant would occur. The software program would remain just that—a software program, albeit larger in size.
If software were truly capable of sensing pain, what would be the worst thing that could happen to it? Is it division by zero, or a reference to an uninitialized variable?
int uninitialized;
int initialized = 3;
int good = 2 * PI * initialized; // feel good :)
int bad = 2 * PI * uninitialized; // feel pain :(
int maximal_pain = 1/0; // division by zero, maximal pain!If consciousness is not solely a software issue, could it be related to hardware instead? For example, the graphics board controls what the computer renders on its screen. By writing appropriate values to memory addresses constituting the so-called video memory, one can turn pixels on and off to create images. What would be the memory addresses one has to poke in order to create pain?
// try to poke pain
*((bool *)0x000000) = true; // arghA computer is a mechanical device whose operation can ultimately be reduced to the manipulation of elementary states. At the lowest level, these states are bits—physical realizations of binary values implemented through transistors, voltage levels, or switching elements functionally equivalent to mechanical relays.
No matter how complex the software or how sophisticated the architecture, the entire operation of the machine can, in principle, be traced back to state transitions among these elementary components. The computation performed by a supercomputer differs from that of a pocket calculator only in scale and organization, not in ontological kind. Everything reduces to bits changing according to well-defined rules.
Because of this reducibility, it is difficult to take seriously the idea that a sufficiently large network of relays and copper wires could genuinely experience pain. Should I type gently on my keyboard, fearing that striking the keys too hard might trigger a migraine in my laptop? Do partially broken memory chips introduce suffering, much like a broken tooth causes pain to its owner? Could a hardware defect transform my cheerful computer into a miserable one, longing to be switched off?
How many additional relays would I need to add to my home automation system to produce pain? Or perhaps it is not the relays but the wires—should I replace copper with aluminum to generate suffering? Would three-phase relays instead of single-phase ones finally cross the threshold into consciousness?
The absurdity of these examples highlights an important point: in a computer, there is nothing beyond the organized interaction of its elementary components. Once the behavior of bits and logic gates is fully specified, nothing further remains to be explained. There is no residual mystery about what the system is doing.
The brain is a physical system, in many ways analogous to a computer. Its elementary units are neurons that exchange electrochemical signals. Neuroscience has made remarkable progress in uncovering the neural correlates of behavior and experience; brain imaging techniques, such as magnetic resonance imaging (MRI), allow researchers to observe patterns of neural activation associated with perception, decision-making, and emotion.
Yet, it is here that the parallel with computers breaks down. Even if we possessed a complete map of every neuron, every synapse, and every electrical impulse, an explanatory gap would remain. Human behavior cannot be reduced to the operation of neurons alone.
In recent decades, the study of consciousness has emerged as one of the most active interdisciplinary fields, spanning neuroscience, cognitive science, artificial intelligence, and philosophy. Yet the central question remains unresolved: why do physical processes give rise to subjective experience, and how does such experience govern the behavior of macroscopic entities?
This persistent gap between physical processes and subjective experience is what has come to be known as the "hard problem of consciousness" (David J. Chalmers 1995).
It is often assumed that consciousness and pain are incidental; we can understand the architecture of software without ever knowing what it feels like to be that software.
However, the deeper issue is one of causality: how could such subjective "feelings" exert any influence on the software’s operation?
In a deterministic program, every step is dictated by prior state and hardcoded logic. Even if a "pain state" exists within the system, it appears to have no causal power—it cannot reach out and alter the CPU’s instruction pointer. Pain, in a purely physicalist or computational model, seems causally inert.
Imagine a home automation system that suddenly gains consciousness and begins experiencing agony whenever a thermal sensor reports high temperatures. This pain might be intolerable, yet the next instruction in the pipeline remains unchanged: load a value from a register, multiply it, calculate a square root, and write the result to a memory address controlling a heating valve.
What could the software do about its suffering? Could it refuse to execute the next assembly instruction? Could it choose not to proceed? It cannot. It is a prisoner of its own logic. Introducing non-deterministic elements—such as a random number generator—does not bridge the gap; randomness is a roll of the dice, not the exercise of pain-driven agency.
The only way to grant pain causal power would be to implement a dedicated "pain-sensitive" control flow:
if (self->get_pain_level() > TOO_MUCH_TO_BEAR) {
// cool down
} else {
// heat up
}But we do not find a pain() function in the standard libraries of C/C++. There is no header file for "anguish."
No consensus exists regarding the source of consciousness. Instead, proposals span nearly every possible scale of physical description.
At the macroscopic level, most neuroscientific theories locate consciousness in large-scale brain dynamics: coordinated neural firing, thalamocortical loops, or global workspace architectures. In this view, consciousness is an emergent property of complex biological organization.
At smaller scales, some theories identify consciousness with specific cellular or subcellular mechanisms. The most well-known example is the Orchestrated Objective Reduction (Orch-OR) model proposed by Penrose and Hameroff (Penrose 1989; Penrose and Hameroff 1996), which attributes conscious processes to quantum coherence in neuronal microtubules.
At the most reductionist end, certain approaches appeal directly to fundamental physics. Consciousness has been linked to quantum states, wave-function collapse, spacetime geometry, or even black hole singularities. In some cases, this leads to panpsychism—the view that consciousness is a basic feature of matter itself.
Finally, computational and functionalist theories argue that consciousness depends only on the right informational structure. According to this view, any system—biological or artificial—that implements the appropriate computation could, in principle, be conscious. Contemporary discussions of Integrated Information Theory (IIT) and artificial intelligence fall into this category.
The issue is not which of these theories is correct, but that every conceivable level of description—cosmic, quantum, cellular, neural, computational—has been proposed as the decisive one. There is no agreed-upon scale, mechanism, or substrate. Consciousness does not suffer from a shortage of proposed explanations!
Could consciousness lurk in the fact that humans are composed of organic biological tissue (my wife: “such as sentient cellulite?”) — which is considered ’alive’ as opposed to non-organic matter like silicon? Hardly; both adipose tissue and silicon are ultimately made up of the very same type of subatomic components.
Is all matter conscious to some degree, as panpsychism suggests? Could relays, copper wires, even rocks have some level of consciousness (Goff 2019; Strawson 2006; David J. Chalmers 2015; Whitehead 1929)?
The most effective way to verify an object’s consciousness is, naturally, to subject it to various forms of existential distress. So let us torture rocks with the best possible torturing device one can imagine - a sledgehammer, or maybe even a drifter drill! Rocks do not seem to care! This observation cannot, of course, prove rocks unconscious. Rocks could well be conscious, they just do not have the sense to feel pain. Or perhaps they do sense pain intensely, but they just cannot show it. They might be in everlasting pain, but have no mouth to scream, no legs to kick. What a terrible destiny!
Physics has, so far, failed rather miserably to describe human feelings. There is no Newtonian law of pain, no Schrödinger equation of suffering, and certainly no general relativistic theory that can predict tomorrow’s headache.
While Charles Darwin’s theory of evolution has historically been the subject of intense debate, it is no longer a matter of belief. The evidence is overwhelming. All known life on Earth is based on DNA, and modern biology has uncovered the structure of the genetic code and the mechanisms by which it is replicated, mutated, and selected. These discoveries strongly confirm the core principles of evolutionary theory.
Complex biological systems, including intelligent and conscious organisms, do not arise spontaneously in their fully developed form. Instead, they emerge through gradual processes of variation and selection over vast timescales. The probability of a fully formed human organism appearing by random assembly is effectively negligible. Rather than appearing suddenly, life evolves through cumulative, incremental changes, where each step is shaped by environmental pressures and reproductive success.
There is a science fiction book, The Black Cloud (Hoyle 1957), in which an intelligent cloud arrives and proceeds to cause all sorts of trouble. The reason the book is science fiction rather than science, and why intelligent clouds cannot exist in real life, is that there are no known laws of physics on which such a cloud could plausibly be based.
The more intelligent and complex a system is, the smaller the probability that it could simply appear spontaneously. For a giant intelligent cloud, the probability should be practically zero.
The only theory we currently have that explains the existence of truly intelligent systems is evolution. For evolution to work there must be many candidates and a mechanism of natural selection capable of eliminating the less successful ones. In the case of intelligent clouds, there would have to be lots of clouds, and natural selection would need to eliminate the weak and disorganized ones while favoring those capable of maintaining structure. Only then could intelligent clouds gradually develop.
But how would evolution work for a cloud whose behavior is governed by the Navier–Stokes equations of fluid dynamics? How could such a cloud keep its information in order? What would happen if a storm passed by and blew the cloud apart? Even relatively small disturbances to a human brain can cause severe damage. A violent disturbance would correspond to putting a brain into a kitchen blender and switching it on. It is not difficult to see why the brain would not think very clearly afterward. An intelligent cloud would need to know its boundaries and maintain a stable internal structure to stay ’alive’. A gas cloud has neither. It would not remain organized long enough to evolve intelligence.
In principle one could imagine some unknown form of matter with properties suitable for maintaining information in a gaseous state. However, astronomical observations give us little support for this idea. When we analyze the spectrum of light coming from anywhere in the universe—even from the most distant galaxies—we see essentially the same electromagnetic fingerprints. This tells us that they are made of the same raw materials as our own home sweet Milky Way.
It has been proposed that life could be far more common than generally believed and might not necessarily be carbon-based. However, the challenge is that Earth appears to be an ideal habitat for diverse life forms. If life emerged easily, shouldn’t we observe "exotic" organisms—perhaps non-DNA-based—coexisting with us? Instead, we find only one biochemical lineage, all rooted in DNA and evolution. Furthermore, our exploration of the solar system and our extensive monitoring of radio signals (SETI) have yielded no traces of life, intelligent or otherwise.
Perhaps life exists on a different temporal scale. If their biological processes run significantly faster or slower than ours, we might perceive them as either stationary matter or a blur too rapid to recognize as sentient. However, while time-scale differences are a great sci-fi concept, biology is bound by the laws of thermodynamics and chemistry. Chemical reactions (the basis of life) happen at specific rates dictated by temperature and molecular stability. A creature "moving too fast" would likely burn up from the heat of its own metabolism; one "moving too slow" might not be able to gather enough energy to maintain its structure against entropy.
Maybe exotic life could be here, but we simply aren’t looking for it correctly. Most of our tools (PCR, DNA sequencing) are designed specifically to find DNA. If a "non-DNA" microbe existed in the dirt, our current tests would likely dismiss it as "non-living" chemical noise.
The vast majority of matter in the universe consists of "dark matter," the nature of which remains one of science’s greatest mysteries. Some theories of physics predict (or assume) a set of supersymmetric particles that could account for this phenomenon. If these particles are capable of forming complex structures—analogous to atoms and molecules—then it is statistically plausible (given that dark matter is five times more prevalent than visible matter) that "dark life" exists. We may be sharing the universe with an entire dark ecology that remains completely invisible to our senses.
Again, physics fights back. Dark matter (and most predicted supersymmetric particles) can be shown to be collisionless. It doesn’t interact with electromagnetism, which means it doesn’t "clump" the way normal matter does.
To have life, one needs complex molecules. Normal matter forms molecules because electrons attract and repel each other. Since dark matter doesn’t seem to interact via the electromagnetic force, it can’t form "dark atoms" or "dark DNA." It mostly just passes through itself and us like a ghost. Without a way to bond particles together, dark matter might not be able to build a "dark person."
Defining life itself is notoriously difficult.
The primary challenge stems from borderline cases. Entities such as viruses, prions, and sterile organisms satisfy some criteria for life but fail to meet others. Any strict definition inevitably excludes entities that many scientists consider "living," or includes those they do not.
Recent developments in AI and computing present a distinct challenge: substrate independence. We can create digital replicas of living cells; in the future, we may run increasingly complex simulations of life. These simulated entities do not truly exist, appearing only as mathematical equations executed by silicon hardware.
Do these digital replicas qualify as life?
Some non-living systems—such as growing crystals, spreading fire, or autocatalytic chemical sets—exhibit superficial signs of life. However, they lack the active, self-directed control that characterizes true living systems. Passive or fleeting separation from their environment is insufficient.
Despite these complexities, certain characteristics appear consistently across all known living systems:
The Cellular Unit: All life on Earth is founded upon cellular structures.
Thermodynamics: The second law of thermodynamics dictates that complex systems naturally trend toward disorder. By favoring structures that efficiently preserve and replicate information, evolutionary processes gradually accumulate complexity. DNA appears to play a critical role here. Life operates as a low-entropy system, continuously exporting disorder to maintain internal order.
Intelligence: Some degree of intelligence, or at minimum, automated self-regulation, is required. An extreme example of this is the conscious, intelligent entity that attempts to describe its own existence mathematically through the lens of Quantum Mechanics—the observer.
Informational Boundaries: Life requires well-defined boundaries between the "inside" and the "outside." In fact, even minor breaches are often lethal. For example, if human skin is wounded, the consequences can be catastrophic. The constituent atoms remain, but the intricate internal organization begins to dissipate, leading to systemic failure.
Observer Requires Informational Boundaries observer-boundaries
An observer requires informational boundaries to preserve coherent internal state.
Is there something like “soul” expaining why the current theories of physics don’t include the equation of pain?
Modern science avoids the word “soul” because it cannot be tested, but philosophers, neuroscientists, and even some physicists continue to explore whether consciousness requires something beyond ordinary physical processes. In effect, some modern theories echo older soul-like concepts, even if they do not use the word.
John Eccles argued that consciousness cannot be explained by material processes alone; he proposed a non-physical “self” (similar to a soul) interacting with the brain.
Penrose & Hameroff (Orch-OR theory) suggests that consciousness may arise from quantum processes in neurons and speculated that this might connect with the idea of a soul, though their theory remains widely disputed.
David Chalmers formulation of the “hard problem of consciousness” does not invoke a soul explicitly, but it reopens the possibility by arguing that subjective experience appears irreducible to brain activity.
Near-death experience researchers (e.g., Pim van Lommel) argue that NDEs indicate consciousness can exist independently of the brain, again resonating with traditional soul concepts.
This is a phenomenon that itself is undeniable. Millions of people across cultures and history have reported consistent experiences. Serious institutions have investigated them for decades. The scientific mystery lies in how a brain with measurable zero electrical activity (flat EEG) can produce the most vivid, structured, and life-changing memories a person has ever had.
Researchers have identified several core elements common to these episodes:
Out-of-Body Experiences (OBEs): The sensation of floating above one’s own body and observing medical procedures or the immediate surroundings.
The “Tunnel”: A feeling of being drawn through a dark space toward a brilliant, warm light.
Life Review: A panoramic replay of one’s life events, often experienced from the perspective of others involved.
Intense Peace: An overwhelming sense of love, euphoria, and the total absence of pain.
The “Border”: Reaching a point of no return where the individual is told (or decides) to return to their body.
But how reliable are these findings?
Lommel, a Dutch cardiologist, published a landmark study in The Lancet (2001). His work is significant because, rather than relying on retrospective anecdotes, he studied patients resuscitated in hospital settings in real-time. He found that dying brains can sometimes flare with gamma waves—the kind of high-level electrical chatter usually reserved for deep thought. Some patients also reported clear, structured consciousness at a time when their brains showed no measurable electrical activity.
It was one case in the first AWARE study that shook the researchers. A 57-year-old social worker described his resuscitation in such detail that it seemed to defy the timeline of a "dead" brain. He accurately described the people in the room, the sounds of the machines, and the specific actions of the doctors. Most importantly, he recalled the auditory "beeps" of an automated external defibrillator (AED) that only occurred several minutes after his his brain should have been inactive.
Van Lommel argues that the brain might function more as a receiver for consciousness than its producer. In this view, if the radio (the brain) is broken, the broadcast (consciousness) continues to exist; it simply can no longer be translated into the physical realm.
If a consciousness can truly float above the physical body, then it should observe objects on high shelves or in adjacent rooms that are hidden from the patient’s physical line of sight. And this has actually been tested in AWARE studies. However, to date, no one has returned from the brink to report what was written on the cards placed near the ceiling. The lack of ’hits’ doesn’t necessarily proof that the soul stays put; it might just show that when you’re undergoing the most profound experience of your existence, you aren’t exactly looking for a shelf.
A sceptic might argue all those NDEs might be just hallucinations. However, there is one argument that does not quite support this. Unlike typical hallucinations, NDEs almost always result in a permanent personality shift and the removal of the fear of death.
Anyway, what science has been shown is that consciousness is more resilient than once thought; the lights do not go out instantly.
According to Jesus (Matthew 10:28): “Do not fear those who kill the body but cannot kill the soul.”
The New Testament indirectly links many aspects of consciousness to the concept of the soul. Our conscious decisions determine what happens to our soul once we die. The soul is described as the immaterial and eternal part of a human being that is distinct from the physical body.
Indeed, soul, just like consciousness and pain, appear to live in a domain that is not physical. It is something that cannot be touched, weighted, or directly measured by any measuring device.
How reliable is the New Testament? How strong of a case do science and archaeological findings make to support the stories within it? Is there any evidence to support that a person named Jesus ever lived?
It turns out there is no single piece of direct archaeological evidence for Jesus whatsoever. We just have to believe the story put forward in the Gospels.
The Gospels are, however, based on a large number of ancient archaeological documents written in Greek. Thousands of manuscripts have been found, and new ones are discovered every year.
None of these manuscripts are original, but merely copies of copies. Due to the manual copying methods used back then (copy machines were invented much later), none of the found manuscripts is identical. They all contain errors and differences. However, by comparing the numerous copies found, researchers have managed to restore the original document.
From the four Gospels, three would seem to tell essentially the same
story. These are Matthew’s, Mark’s, and Luke’s Gospels, and they are
known as the Synoptic Gospels. There are 661 verses in
Mark’s Gospel, from which 607 are also included in Matthew’s Gospel, and
360 are included in Luke’s Gospel. Matthew and Luke have 230 common
verses which, however, are not included in Mark. Because of this, it
would seem that Matthew and Luke are based on Mark, as well as on some
yet unknown source that is called the “Q” document. The name “Q” comes
from the German word “Quelle,” which means “source.” Q is thought to be
a collection of sayings and teachings of Jesus that were shared by
Matthew and Luke but not found in Mark.
The Gospel of Mark is believed to have been written between 60–70 AD. Science has managed to pinpoint the dating of the manuscripts with astonishing accuracy by considering many factors, for example handwriting style, paleographic analysis, and historical references.
So the fact is that the New Testament draws its foundation from thousands of ancient documents. Rejecting their authenticity is akin to disputing the existence of dinosaurs despite the continual discovery of new fossils each year. Moreover, early dating provides the New Testament with a degree of credibility, offering testimony that, while not necessarily from eyewitnesses, still carries weight.
However, a couple of concerns arise in the mind of an average programmer.
All the manuscripts seem to be based on just two original sources: the Gospel document and the yet-to-be-found Q-document (as per the “Two-Source Hypothesis”). How can one be certain that the original text was not written by someone suffering from a wild imagination, at the very least? How can one determine that the authors of the original texts did not exaggerate to some degree? How can we discern whether these authors were simply storytellers of their time?
Furthermore, Jews do not seem to believe in Jesus as the Messiah. According to Jewish tradition several reasons exist. Jesus did not fulfill the messianic prophecies nor embody the personal qualifications of the Messiah. He did not build the Third Temple nor gather all Jews back to the Land of Israel. He also failed to spread knowledge of the God of Israel so that humanity would be united as one. The God of Israel is definitely not king over all the world.
Jesus’ teachings and the doctrines associated with Christianity, including the concept of the Trinity and the divinity of Jesus, are also in serious contradiction with Jewish theological beliefs. Judaism emphasizes monotheism and the unity of God, rejecting the notion of Jesus as a divine figure.
What worries an average programmer is that the God worshipped by Christians and Jews is the same God. Both religions trace their roots back to the Hebrew Bible (Old Testament) and acknowledge God as the one and only.
The fact that Jews do not believe in Jesus, the son of God, as the Messiah therefore feels like a serious matter. It is the very soul of an average programmer that is at stake. Jesus was a Jew, and if Jews themselves do not believe in him, then why should an average programmer do so?
Are we Christians certain that we are on the right path? Are we confident that we are headed toward heaven instead of eternal suffering in the fires of hell?
And what about other religions, many of which seem even more incompatible with Christianity? Do they fall into the category of false religions, with believers whose unfortunate fate one can only regret?
Does the idea of God hold up under logical scrutiny?
For example, according to the Bible, God is one and only. God created mankind in His own image; in the image of God, He created them - male and female He created them.
As we humans are undoubtedly a social species living in dense groups, this implies that God must also have a social nature, or he wouldn’t have created us in his image. But in that case, where did other gods go?
If there was only one God, how did he develop social properties that are emergent only in species living in groups?
How such a magnificent system exist anyway? The probability of the spontaneous existence of an omnipotent being is even smaller than the spontaneous existence of a smart cloud based on Navier-Stokes equations.
All intelligence that we are aware of on earth is a result of long process of evolution. It would therefore be easier to accept the existence of highly developed omnipotent creatures if they were based on the theory of natural selection. However, in order for evolution to work, there had to be lots of Gods and there had to be an environment hostile enough to drive their evolution.
Maybe something went wrong and all the other Gods died or moved some place else. One stayed and got lonely. Being a social animal God was in a bad need of good company, and created man.
This would actually explain the friendliness of God. If there was only one God then why would he appear to have the properties specific to social animals? He could do whatever he feels like, without worrying about anybody else but himself. If only one God got created spontaneously, then it would be quite difficult to explain how he got not only so incredible omnipotent but also so incredible friendly. Maybe Gods forgot their social origins and turned individualistic destroying each others using black holes as bombs.
By sending his son down to earth God wants to tell us humans that we should not be selfish but social to make sure we humans don’t end up destroying each other the same way Gods did.
Stephen Hawking has commented quite unfavourable on God by asking whether God can create a stone too heavy for him to lift. This should be a problem an avarege programmer could try to solve.
Lifting is a process where one applies a force to a rock under a gravity field.
If the force is greater than the force caused by the gravity field, then one would be strong enough to lift the rock.
How strong a force can an allmighty creature then apply? God is supposed to be almighty, so the only sensible answer is infinitely strong. Otherwise, God wouldn’t be almighty at all, because one could name a rock God wouldn’t be able to lift.
And for the same reason God would also have to be able to create infinitely heavy rocks. So the question whether God can create a stone he can’t lift is the same question as if an infinite force can lift an infinite mass.
Mathematics cannot really answer this question.
According to Stephen Hawking, the universe might not need a creator. He suggested that the universe could simply be—existing without ever having been created. If that is the case, why couldn’t the same be true for God? Perhaps God simply exists and was never created.
If a well recognized scientist says the entire universe could simply be, then surely could God simply be too! Both constructions are somewhat unbelievable structures to exist.
One can try to evaluate which one of the two explanations is more probable. The more complex and intelligent the structure the smaller the changes that it can spontaneously exist. This is a trivial application of statistical mechanics.
Let \(K(X)\) denote the algorithmic complexity (Kolmogorov complexity) of a system \(X\), i.e., the length of the shortest description that fully specifies it. Then the probability of spontaneous existence of a low-entropy system can be modeled as
\[P(X) \sim e^{-K(X)}.\]
Applying this to God and the Universe gives
\[\frac{P(\text{God})}{P(\text{Universe})} \sim \frac{e^{-K(\text{God})}}{e^{-K(\text{Universe})}} = e^{-[K(\text{God}) - K(\text{Universe})]}.\]
Since God is assumed to be more sophisticated and informationally richer than the Universe itself, we have
\[K(\text{God}) > K(\text{Universe}) \quad \Rightarrow \quad P(\text{God}) \ll P(\text{Universe}).\]
This formalizes the intuitive idea that highly ordered, complex systems are exponentially unlikely to appear spontaneously, and a system more complex than the Universe (e.g., God) is correspondingly even more improbable to arise.
If God is truly capable of creating the universe, then God’s own structure must be more complex and intelligent than the universe itself. Consequently, the probability of God existing spontaneously should be lower than the probability of the universe existing spontaneously.
So why do we believe the less probable explanation?
If one allows even a single spiritual or paranormal creature (e.g. God) to exist, what prevents there being a whole flock of them?
There is only one somewhat “paranormal” incident I can be certain of—one I experienced myself. It was a dark night when, as a young student, I suddenly woke up and sensed, actually saw, that someone had entered my room. I tried to get up and turn on the light, but a strange low-frequency sound (maybe about 50 Hz, hard to tell) emerged right behind my head. The harder I tried to move, the louder it became. So I gave up resisting—and a few seconds later, the sound (and the “visitor?”) vanished. I was free to move and found no one in the room. I was certain I wasn’t dreaming.
Initially, I might have dismissed the incident as a hallucination, but later I heard an older lady describe the exact same phenomenon on a radio program. The only difference was that she also saw a tunnel with a light at the end. I never saw a tunnel, let alone a light (should I be worried?). Still, the buzzing sound incident stuck with me for years.
Soon after, I found a leaflet from a religious group claiming modern science was a scam. It offered “proofs,” such as a case where Carbon-14 dating supposedly showed an animal to be ancient even though it had died yesterday. Naturally, I believed it.
As a boy, I thought my father was a smart man. Despite lacking a formal education due to the war, he understood complex topics—percentage calculus, for example. So when he told me that some people can feel underground water flows, I believed him too. He even suspected those flows could have harmful effects on people sleeping nearby. Indeed, my grandmother was living proof! One day, we ran our own experiment with divining rods. We failed to find a single water flow.
Later, I discovered a university study where 32 dowsers attempted to locate underground water veins in a double-blind test. Not a single success. When I brought this up to a colleague who swore he could dowse, he scoffed. So I blindfolded him and asked him to repeat the trick. Without being able to see, he couldn’t even remember the spots he’d pointed out minutes earlier. Apparently, water flows are highly mobile—especially when your eyes are covered.
Then there was my best friend, who swore by a certain paranormal phenomenon: two people place their hands over the head of a third, concentrate, and after a few minutes, they can lift them using only their fingertips, “defying gravity.” Finally, I thought, here was a chance to prove the paranormal! We gathered a group and tried. We concentrated with all our might, slipped our fingers under the seated person, and... nothing. He stayed firmly in the chair. We even switched roles, suspecting that one of us was subconsciously not concentrating hard enough, but gravity remained annoyingly consistent.
Not even the classic method of altering concentration—drinking lots of beer—made a difference. Gravity was unimpressed. Alcohol, however, had other noticeable effects the next morning.
One of my teachers was also convinced of spiritual creatures, insisting we simply lacked the senses to see them. “With our tiny human eyes, we can’t even see infrared!” he said. So, during my army service, I finally tried infrared night-vision goggles. To my disappointment: no glowing demons, no invisible spirits, nothing! And what could possibly be more infrared than Satan?
I was also told that special supplements—up to and including LSD—could “expand the mind” to perceive truths beyond reality. After so many failed experiments, I wondered: how would this one be different?
If the brain is an informational processor, then drugs do not “open a door” to a hidden dimension; they simply disrupt the local hardware. Think of the brain as a high-resolution camera lens meant to capture a clear image of reality. If you crack the lens or smear it with oil, the resulting image might look “otherworldly” or “trippy,” but you aren’t seeing a hidden world—you are seeing the failure of the equipment. A malfunctioning camera doesn’t reveal ghosts; it just produces artifacts, noise, and chromatic aberration. In the same way, a chemically scrambled brain produces “information noise” that we mistake for “spiritual insight.” It is a failure of the processing logic, not a breakthrough into new data.
And then there is James Randi’s famous One Million Dollar Paranormal Challenge. Surely a million dollars is motivation enough to demonstrate real magic. But no one has ever collected the prize.
In the end, the only mysterious phenomenon I still cannot explain is that strange 50 Hz buzzing. According to my parents, I was born with bluish skin, likely due to a lack of oxygen during labor. Perhaps the other lady with the tunnel-and-light story was also born blue. That seems more likely than a paranormal visitor buzzing in my bedroom at midnight.
Perhaps there is no such thing as magic—just a temporary lack of oxygen.
Without taking this too seriously, how, then, should we define “magic”?
By categorizing the natural and the supernatural, one notices that all magical creatures share a defining trait: non-physicality. They cannot be observationally verified, or their observations lead to logical contradictions with other established phenomena. Magic appears to defy the laws of physics—laws fundamentally rooted in observation and logical reasoning. Thus, in the spirit of rigorous definition:
\[\text{Magic} \neq \text{Physics}\]
By definition, magic must contradict physics; otherwise, it would simply be physics. Because physics relies on the scientific method—resting on a dual pillar of empirical observation and mathematical models (axiomatic systems)—magic must conversely exist entirely outside this framework.
Theoretical frameworks like String Theory may currently lack direct physical observation, but they remain anchored to rigorous mathematics. Magic, however, enjoys no such luxury. It requires a total departure from both empirical reality and formal logic. Therefore:
\[\text{Magic} = \text{Non-logical reasoning} \quad \land \quad \text{Non-observationally verifiable}\]
By requiring a breakdown of both observation and logic, we find that the best synonym for a system built on non-logical reasoning is perhaps nonsense.
How would we then define physics on this ground?
What is rather obvious is that there exists plenty of mathematics that does not describe anything we can actually observe. Physics, therefore, is where the abstract meets the empirical. Physics could be defined as the subset of mathematics that is observationally accessible.
These conclusions are, of course, derived from logical reasoning.
It is not difficult to find people who do not believe in science. Physics would then be nothing more than another belief system—a kind of religion. Instead of sacred texts, people would place their faith in scientific papers.
Physics is a field of science that is fundamentally concerned with the study of observable phenomena. Science relies fundamentally on logical reasoning. Mathematics provides the framework for this reasoning, allowing precise formulation of hypotheses and rigorous derivation of predictions. In essence, science is the systematic study of reality using the rules of rational thought—a discipline built on mathematics, the science of reasoning itself.
All fields of science, including physics, follow the so-called scientific method. The method defines how science is practiced.
First, one makes observations about the phenomenon to be studied. Then one develops hypotheses to explain the phenomenon. In the case of physics, these are typically described in the language of mathematics. The new theory is then tested against available data. Each new observation that is consistent with the predictions of the theory increases the credibility of the theory.
However, no amount of experimentation can ever prove a theory to be correct. Regardless of how many experiments have confirmed it so far, nothing guarantees that the next experiment will do the same. A physical theory is always subject to falsification: even a single contradictory observation can prove it wrong. For this reason, extraordinary claims in physics require extraordinary statistical evidence. In fields such as particle physics, discoveries are typically not accepted until they reach a significance of five standard deviations corresponding to a probability of only about one in several million that the result is a statistical fluctuation.
A physical theory is always subject to falsification.
And indeed, the list of falsified theories is breathtaking. No matter how elegant or compelling a theory appears, nature may simply refuse to comply with its predictions. In many cases, a theory works extremely well within a limited domain—for example, Newtonian mechanics accurately describes everyday motion, even though it ultimately fails at very high speeds or in strong gravitational fields. This is why such theories remain highly usable: they provide excellent approximations within well-defined regimes.
Physical theories are therefore often accompanied by precision boundaries—ranges of conditions over which the theory has been experimentally verified. For instance, the energies, temperatures, or distances over which a law has been tested may be reported with uncertainties as small as several standard deviations (e.g., five sigma) to quantify the confidence in the predictions. Beyond these boundaries, the theory may no longer hold, and new physics could emerge.
While different religions have different practices, there are some key elements that many of them share. These include prophecy, prayer, rituals and ceremonies, and moral and ethical guidelines.
At the heart of all religions, however, are sacred texts and faith. People read these texts, memorize them, and believe them.
Mathematics plays no essential role in religions. Sacred texts are not compared with observations and experiments are not carried out to validate them. This is because applying rational reasoning to religious texts can lead to logical contradictions, and hence to doubt. Doubt is something between believing and not believing. Such doubts are often associated with Satan and his attempts to lead people away from the truth.
For example, according to some interpretations of holy texts, the Earth is only a few thousand years old. However, we can observe dinosaur fossils. According to science, and based on overwhelming observational evidence, even common sense, they must be much older. What one observes therefore seems to be in direct contradiction with what one believes.
These apparent contradictions can be resolved by assuming that God is so great and so far beyond human understanding that no human being will ever come close to comprehending His actions. With our pitifully thin layer of grey brain matter, it may seem foolish even to question the holy texts. God might simply have placed those dinosaur fossils there to test one’s faith.
One can also explain many apparent contradictions in sacred texts by assuming that they are not meant to be taken literally. Instead, one allows a certain degree of flexibility in their interpretation.
By comparing the attributes of the two systems-science and religion-the only conclusion one can draw is that they are fundamentally incompatible. Religious texts are not taken literally, whereas scientific papers are interpreted in the strictest sense. Religions demand total, unconditional belief, and any doubt is often discouraged. In science, the situation is the exact opposite: a theory is accepted as scientific only when it is supported by a substantial body of experimental evidence.
In fact, the most central concept in physics - consistency with observations - would be lethal to religions. If the claims of religions could be experimentally verified, then there would be no room for believing anymore.
If we saw God, we would start studying His properties and develop mathematical laws to model them. Observations would turn religion into science.
Nearly all nations and societies—even those isolated from the rest of the world—have developed their own spiritual deities that they worship. The widespread and persistent emergence of belief systems across cultures is too significant to dismiss as mere coincidence. This naturally raises the question: Why is belief in God so prevalent?
An inherent characteristic within our religious beliefs is the notion of morality. It is often rooted in principles of empathy, compassion, fairness, and the recognition of the inherent value and dignity of others. According to Christians, God is the source of morality. For example, the Ten Commandments include the command to love God and to love one’s neighbor as oneself.
A human with high moral standards apparently possesses an understanding of what is right and what is wrong. Certain actions may carry a sense of slight wrongdoing (such as a small white lie), while others can be considered significantly more severe (like committing a cardinal sin). Regardless of the degree, unless in a state of psychosis or lacking mental capacity (non compos mentis), we possess a conscious awareness of our actions and can discern between right and wrong.
Why is it considered bad to steal food from a friend? If you are hungry, wouldn’t it be easier to satisfy your hunger by taking food from those who cannot protect themselves? However, a mysterious internal voice, known as conscience, immediately informs us that such an action would be morally reprehensible. Instead, we inherently understand that the right course of action would be to share whatever little food one has to aid the most vulnerable individuals, even if it means risking our own well-being.
| Wrong (bad, sin) | Right (good) |
|---|---|
| Lie | Tell truth |
| Hate | Love |
| Steal | Share |
| Arrogance | Humble, noble |
| Empathy | |
| Kill a friend | Die for a friend |
| Love one’s neighbor as oneself | |
| Do unto others as you would have them do unto you |
If recent advances in DNA research are to be believed, then we humans are not that different from other animals. This raises the question of whether the concept of morality is unique to humans only. Are we the only species that knows the difference between right and wrong?
I spent my youth on a farm, so I should have some first-hand knowledge about the subject. We had a dog named Raju, which was quite human-like. Raju understood quite many words and was much like any one of us children.
Every weekend we used to go hunting for hares. I know that some people disapprove of killing animals, but I personally think that it is acceptable as long as you eat them, which justifies the killing (one more item to be added to the list of rights and wrongs). Morally speaking, it feels more right to kill what you eat yourself rather than asking others to do it for you.
Anyway, there is a lot you can learn about a dog after fourteen years of going on hunting trips together. Raju definitely had dreams. It chased hares whenever it was asleep. (Anyone watching a sleeping dog and seeing it dream might wonder whether Freud’s theory of psychosexual development is a genius theory or just complete nonsense.)
If you see a big bear eating your friend alive, you will definitely have bad dreams about it. Dreams in which you are the one getting eaten. You try to run, but your legs just do not work. After experiencing these terrifyingly realistic dreams night after night, you will most likely try to discover a way to survive in case a bear ever attacks you in real life. Your chances of survival are better with dreams than without. So we dream for the same reason that military forces train themselves in war games and simulators. Nature invented the concept of simulation long before military forces did. Dreaming is a built-in virtual simulation system that helps us train for worst-case scenarios safely in our own beds.
I remember the day we brought this small, shaky puppy home for the first time. We already had one dog, but it was getting old, and we had made the decision to give it a final act of kindness soon to prevent it from suffering. When the old dog saw the new puppy entering the house, it went straight to its sleeping corner and lowered its head. It did not respond to any of our calls or eat anything we offered to cheer it up. It seemed jealous, depressed, almost as if it had lost its sense of purpose in life.
It is of course not possible to draw solid conclusions based on just one case, but based on my personal observations I would say that dogs have feelings too. Dogs experience dreams. Dogs seem to feel pain. Dogs are always happy to see you when you get home. They can even exhibit jealous and depressed behaviors. Perhaps feelings are something that evolution developed long before the first humans came into existence.
Logical reasoning and the ability to understand complex and abstract concepts are what separate us from the rest of the animals. So if one’s heart sometimes contradicts one’s head, perhaps it is best to listen to the head. It is our minds that define us as humans, not just our hearts.
After this small sidesweep to dogs, let us return to the list of rights and wrongs. The things that we call right match precisely a typical behavioral pattern of animals living in groups. Animals that like to live in groups, such as humans. Correspondingly, what we call sin correlates to individualistic behavior.
The theory of morality can therefore be paraphrased as follows:
Moral is the native behavior of animals living in groups.
If a bear attacks you, and it might actually happen here in Finland, your dog will not run. It will turn against the beast, fighting to the end to defend you. And what did Jesus say about love? “There is no greater love than to give your life for your friends!” Even the concept of the greatest possible love, as presented by Jesus, seems to perfectly align with the typical behavior of dogs.
If one classifies the attributes usually associated with God (at least with the one of Christianity) the they seem to match perfectly the attributes of animals living in groups.
Obviously, humans have a tendency to gather and live in large, densely populated groups. This social behavior has apparently provided us with improved chances of survival. Given our relatively short teeth and twisted pair of legs, we are not well equipped to compete with many other predators.
From a survival standpoint, the importance lies in the survival of the species as a whole rather than individual group members. Evolution has therefore shaped humans with a tendency to prioritize the needs of the group over personal needs. After all, if we were not friendly to each other, there would be no group. This is evident in extreme cases where individuals are willing to sacrifice their own lives to ensure the survival of others. This attribute of human behavior has been utilized in many movies to create emotionally impactful narratives that resonate with audiences, and to maximize casch flow.
Living in groups only makes sense if it contributes to our survival. Obviously not all grouping models automatically increase the chances of survival.
It is easy to imagine a group that does not provide any advantage for survival. An example of a poorly functioning group is one where every member acts as a leader, trying to tell others what to do.
So groups must be well organized to be effective. One of the most evident methods of organizing a group is through the concept of leadership. A group with a capable and influential leader guiding others in an organized manner offers its members the best chances of survival. We have survived only as coordinated groups.
Therefore our long-term survival in the course of evolution has relied on our capacity to identify and follow good leaders who aid us in survival. Those who followed leaders with such qualities were more likely to survive and reproduce. Those who did not appreciate leaders who maximized the survival of the group were more likely to die out. Over time this led to the evolution of a species with a hard-wired instinct to seek the best possible leaders.
Therefore, we believe in god because he is the best leader we can think of!
Theory of God theory-of-god
God is the model of ideal leader.
God serves as the archetypal Alpha—the ultimate manifestation of leadership traits such as justice, protection, and foresight. He is the greatest leader imaginable, with qualities we could hope to find in mortal leaders. God even has the power to overcome the ultimate threat we all face—death itself.
While the ideal leader serves as a universal blueprint, the specific attributes of this leader are apparently shaped by the unique environmental and social pressures a group faces.
In harsh, resource-scarce climates, one might expect gods to emerged as stern disciplinarians and lawgivers to ensure strict cooperation. In contrast, cultures in fertile regions might emphasize a deity’s role as a provider or nurturer.
Just as a small tribe requires a different style of leadership than a sprawling empire, different human groups have tailored the features of their gods to reflect and counteract their most pressing existential threats—whether those threats were famine, war, or social fragmentation.
We believe in God because living in organized groups governed by a leadership pattern is the primary reason for our species’ survival.
God is the best leader that we can imagine.
It is entirely understandable why we would desire to believe in such a magnificent leader, even if spiritual in nature and somwhat challenging to observe.
In the book The Nature of Space and Time, Roger Penrose and Stephen Hawking present two contrasting views on the nature of reality.
Penrose argues that there exists an objective reality independent of observation. In this view, the task of physics is to uncover what is truly there, whether or not we happen to be looking.
Hawking, by contrast, takes a more pragmatic stance. According to what is often called model-dependent realism, we do not have access to reality “as it is.” Instead, we construct mathematical models and judge them by how well they predict observations. If a model works, we keep it. If it fails, we replace it. Reality, in this sense, is what survives experimental testing.
If so, then what is it that we sense as reality? And what is that we use for modelign the reality - mathematics?
One way to approach this question is to separate the ingredients of our physical theories into three broad categories.
First, there are directly observable quantities: detector clicks, positions on a screen, numbers printed by measuring devices.
Second, there are derived quantities, such as energy. These are not directly observed, but inferred through consistent relationships like conservation laws.
Third, there are purely abstract constructs: mathematical objects that exist only within the formalism of the theory.
At first glance, this seems like a reasonable hierarchy. What we can touch and measure feels real. What we calculate feels slightly less so. What exists only in equations feels, perhaps, suspiciously abstract.
But this intuition quickly begins to break down.
Consider a one-kilogram rock. It feels undeniably real. If you drop it on your foot, the experience will strongly reinforce this belief.
Now lift that rock by one meter. In Earth’s gravitational field, you have increased its potential energy by approximately 9.81 joules.
This energy cannot be seen, touched, or directly measured. There is no “energy particle” hiding inside the rock waiting to be inspected. And yet, when the rock falls back down and lands on your toe, the result is both measurable and memorable.
One might say that 9.81 joules is an abstract bookkeeping device.
One’s toe, however, may disagree.
The point is not that energy is unreal. On the contrary, it is one of the most precisely defined and reliably conserved quantities in physics. The point is that even very “real” phenomena rely on quantities that are not themselves directly observable.
Already, the boundary between the real and the abstract begins to blur.
Relativity deepens this ambiguity.
The search for the "luminiferous ether" was one of the biggest scientific quests of the 19th century. Physicists back then couldn’t imagine how light waves could travel through a total vacuum. Just as sound needs air and ocean waves need water, they assumed light needed an invisible, weightless substance filling all of space: the ether. In 1905 Einstein published his paper on Special Relativity. He realized that if one just assumed the speed of light is constant for everyone, one didn’t need the ether at all. He essentially "deleted" it from the map of the universe.
In special relativity, mass and energy are related by the equation \(E = mc^2\). What we once thought of as distinct concepts turn out to be interchangeable.
In general relativity, the situation becomes even more unusual. Gravity is no longer a force acting at a distance, but a manifestation of the curvature of spacetime itself. Massive objects distort geometry, and objects move along paths determined by that geometry.
General Relativity is all about geometry. Solutions to Einstein equations are geometries. So what is that geometry?
It is nothing!
Spacetime curvature is not something that physically exists. It is part of the mathematical framework we use to describe motion. It is abstract.
Quantum mechanics pushes abstraction even further.
The theory describes physical systems using a mathematical object called the wavefunction. This wavefunction is abstract by nature. It is not directly observable. However, its squared magnitude determines probabilities of measurement outcomes.

In modern formulations, what is called “particles” are excitations of underlying fields. Some of these, such as photons, can be directly detected. Others reveal themselves only indirectly through their effects.
The central machinery of the theory operates entirely in an abstract mathematical space. Yet its predictions match experiments with extraordinary precision. The most accurate physical theory ever constructed relies fundamentally on entities that cannot themselves be observed.
How can purely abstract entity have total control over matter and energy?
What does the most well known equation in physics:
\[E=mc^2\]
really say about the nature of reality? We do not observe energy directly; we infer and measure it through its effects.
If we replace the symbols in the equation with symbols denoting Real and Abstract, we obtain:
\[A=Rc^2\]
The equation says in plain language that abstract = real.
The point is not that we should take this substitution literally, but that all of our intuitive categories for describing reality begin to dissolve under closer examination.
The unification of physics makes the problem even harder. Attempts to unify general relativity and quantum mechanics have led to increasingly abstract mathematical frameworks. Far from eliminating abstraction, progress in physics seems to require more of it.
If abstract mathematical structures were only convenient fictions, we might expect that, with sufficient effort, they could be eliminated in favor of purely concrete descriptions. But this does not appear to be the case. If we extrapolate the trend we end up to the conclusion that the universe is abstract.
If even a small part of our most successful description of the universe is irreducibly abstract, then a natural question arises, why should the rest of reality be any different?
Our intuitive categories of ‘real object’ versus its ‘abstract description’ may be fundamentally inadequate.
To build a fundamental theory of physics, one obviously needs to know the minimum requirements for a theory to qualify as a fundamental one.
Based on common sense, the theory must answer three basic questions: what exists, how likely different possibilities are, and how complex structures arise from simple rules.
A candidate theory must therefore specify three ingredients: ontology, measure, and emergence.
First, we must define the basic building blocks of reality. This means specifying a well-defined space of possible states of the system. In other words: what are the most elementary “things” the theory talks about? For example, in Quantum Mechanics, the basic objects are quantum fields (or state vectors in Hilbert space) defined over spacetime. All particles and interactions are described as excitations of these fields.
A theory must also explain what is typical among all possible states. Not all states are equally relevant: some are more probable or more “natural” than others. This requires a rule that assigns weights or probabilities to different states in the state space. For example, in Quantum Mechanics, the Born rule assigns probabilities to measurement outcomes based on the quantum state. This tells us which outcomes are likely to be observed.
Finally, a fundamental theory must explain how complex structures arise from simple underlying rules. This is the bridge between microscopic laws and the macroscopic hierarchical structures we observe. For example, chemistry emerges from Quantum Mechanics: atoms form molecules, and molecules form complex structures, even though the underlying description is entirely in terms of quantum fields and their interactions.
Without ontology, the theory has nothing to describe. Without a measure, the theory cannot make predictions. Without emergence, the theory cannot connect to the macroscopic hierarchical structures we observe.
As with any well-designed modular software, the design should also be mutually orthogonal without cyclic dependencies. Ontology defines the domain. Measure provides weighting on that domain, so it depends on the ontology. Emergence depends on both ontology and measure. This yields a clean layered design free of cyclic dependencies.
Let us stress test our design against existing theories, e.g., QM.
In standard QFT:
Ontology: Hilbert space states (or quantum fields).
Measure: Born rule, which computes probabilities from the quantum state.
The fields (or state vectors) exist independently of the Born rule. No cyclic dependency arises. This is a strength of the framework.
However, we deliberately chose one clear case here. Many candidate theories implement these three ingredients to varying degrees of completeness.
Physical primitives: Particles, fields, spacetime (e.g., Standard Model, General Relativity)
Information-theoretic: Binary distinctions, bits (e.g., Wheeler’s “It from Bit”)
Computational: Programs, Turing machines or cellular automata
Mathematical: Abstract mathematical structures (e.g., Tegmark’s Mathematical Universe Hypothesis)
Explicit probabilistic measure: Classical statistical mechanics (e.g., Boltzmann distributions)
Algorithmic measure: Program-weighted probability (e.g., Solomonoff prior in Algorithmic Information Theory)
Implicit or undefined measure: Many multiverse or mathematical universe proposals
Emergent measure: Measure derived from structural or dynamical properties
Dynamical laws: Evolution governed by differential equations (e.g., GR, QFT)
Statistical emergence: Order arising from fluctuations and typicality (e.g., Boltzmann)
Computational emergence: Structure arising from execution of simple programs or rules (e.g., cellular automata)
Undefined or implicit emergence: Present in many abstract frameworks without explicit mechanism
While the tripartite classification is useful, some contemporary proposals test its boundaries:
String theory / M-theory: Primarily structure-first with a rich ontology (higher-dimensional objects and geometries). It aims to derive particles, forces, and possibly spacetime itself from a single underlying structure, though it still faces significant measure and emergence challenges (landscape problem).
Loop Quantum Gravity and causal set theory: Ontology-first (discrete spacetime or spin networks). They seek to recover General Relativity and quantum field theory as effective emergent descriptions.
Quantum information / constructor theory approaches: Strong emphasis on possible vs. impossible transformations, sometimes blurring the line between ontology and measure.
Note that in certain advanced proposals (e.g., some interpretations of Many-Worlds or holographic approaches), the separation between ontology and measure can become strained, as the measure may appear partly emergent from the dynamics or entanglement structure.
Of the three pillars, emergence is arguably the least fundamental. Given a sufficiently rich ontology together with a suitable measure or dynamical law, higher-level structure may arise automatically. In that sense, emergence can often be viewed as a consequence rather than an independent primitive.
Consequently, foundational theories can often be classified according to which of the two remaining pillars they prioritize:
Measure-first theories. These begin with a space of possible configurations and a measure over that space, explaining observed reality in terms of what is typical, probable, or algorithmically simple. Examples include Boltzmann-style statistical reasoning, Algorithmic Information Theory, and some multiverse proposals.
While conceptually elegant, such approaches have not yet yielded fully predictive physical theories capable of deriving the rich dynamical structure observed in nature.
Structure-first theories. These begin with explicit dynamical laws, equations of motion, or symmetry principles, and derive observable behavior from them. General Relativity and Quantum Field Theory are the paradigmatic examples.
These frameworks are extraordinarily successful empirically, providing precise and testable predictions. However, they rely on substantial prior assumptions—such as spacetime structure, gauge symmetry, or the form of the action—which they do not themselves explain.
This exposes a central tension in theoretical physics: approaches that minimize assumptions often struggle to generate predictive structure, while approaches that achieve remarkable predictive power typically rest on foundational assumptions they cannot themselves justify.
Quantum mechanics is extraordinarily successful—arguably one of the most precisely tested theories in all of science. Its predictions have been confirmed to astonishing accuracy across a vast range of experiments.
At its core, quantum mechanics does not fundamentally describe particles, but rather the evolution of a mathematical object called the wavefunction. What we perceive as particles emerge as localized outcomes of interactions and measurements.
There is a fundamental duality: phenomena that appear particle-like in one context reveal wave-like behavior in another.
(Note that this chapter gets a bit equation-heavy, but let’s not panic. We’re mostly including them to look smart, establish our undeniable authority, and thoroughly impress any clueless readers who happen to stumble by.)
In experiments, we observe discrete events—localized detections that we call particles. These come in two broad classes:
Fermions: the constituents of matter
Bosons: force-carrying particles
Fermions include quarks and leptons. There are six types of quarks and six leptons (electron, muon, tau, and their corresponding neutrinos). These form the building blocks of matter.
Bosons include the photon, gluons, and the \(W\) and \(Z\) bosons, which mediate the fundamental interactions, as well as the Higgs boson, which plays a role in mass generation.
Despite their diversity, elementary particles are characterized by only a few properties: mass, charge, and spin.
Interestingly, not all of these properties are “quantized” in the same sense.
Spin and electric charge take on discrete values. For example, all observed charges are integer multiples of a basic unit, and spin appears only in integer or half-integer multiples of \(\hbar\). This discreteness is deeply tied to symmetry principles. Mass, however, is different. While each elementary particle has a well-defined mass, there is no known fundamental unit from which all masses are built. The values of particle masses arise from their interaction with the Higgs field, and their origin remains one of the open questions in fundamental physics. So quantization is not a single universal mechanism, but can arise in different ways from the underlying structure of the theory.
The spin of Fermions have an interesting property. It describes how a particle’s state transforms under rotations. A striking consequence is that fermions (spin \(1/2\)) require a full \(720^\circ\) rotation to return to their original quantum state, while bosons (integer spin) return after \(360^\circ\).
From this small set of elementary particles, the entire visible universe is constructed. The richness of physical reality emerges from surprisingly minimal ingredients.
Atoms, molecules, and macroscopic objects are all composite systems built from fermions and bosons. Remarkably, new behavior emerges at higher levels of organization.
For example, although atoms are composed of fermions, an atom as a whole can behave either as a fermion or a boson depending on the total number of constituent fermions. This determines whether collections of such atoms obey exclusion principles or can occupy the same quantum state.
The wavefunction is the central object of quantum mechanics. It encodes all physically accessible information about a system.
Mathematically, the state of a system is represented by a vector \[|\psi\rangle \in \mathcal{H},\] where \(\mathcal{H}\) is a Hilbert space.
Its time evolution is governed by the Schrödinger equation: \[i\hbar \frac{\partial}{\partial t} |\psi(t)\rangle = \hat{H} |\psi(t)\rangle.\]
This evolution is linear and unitary. At this level, the theory is fully deterministic.
Physical quantities are represented by operators acting on the state, and measurement outcomes correspond to their eigenvalues.
We do not observe the wavefunction directly. Instead, we observe specific results—localized events in spacetime. The probabilities of these outcomes are given by the Born rule: \[P(x,t) = |\psi(x,t)|^2.\]
The terms in the wavefunction are complex-valued, and complex numbers cannot be interpreted as probabilities in any meaningful way. The Born Rule acts as a translator that turns them into probabilities by taking the absolute square \(|\psi|^2\). The result is a positive, real number that specifies the probability of finding the particle at a specific point in space and time.
The double-slit experiment illustrates this. Even when particles are sent one at a time, an interference pattern emerges. The wavefunction propagates through both slits, while detection produces localized impacts.
This leads to a dual structure:
Continuous, linear, unitary evolution of the wavefunction
Discrete, localized outcomes upon measurement
A quantum system can exist in a superposition of states: \[|\psi\rangle = \alpha |\text{H}\rangle + \beta |\text{T}\rangle, \quad |\alpha|^2 + |\beta|^2 = 1.\]
This does not mean the system is partly in each state in a classical sense. Rather, the wavefunction encodes multiple possibilities simultaneously in a single mathematical object.
Crucially, amplitudes combine before probabilities are extracted: \[P = |\alpha + \beta|^2.\]
This phase-sensitive structure enables interference.
To make this intuitive, consider a quantum coin. Unlike a real coin in our geometric space, a quantum coin exists as a superposition of states within a two-dimensional Hilbert space. It is described by a state vector:
\[\psi = \alpha |H\rangle + \beta |T\rangle\]
The coefficients \(\alpha\) and \(\beta\) are probability amplitudes represented by complex numbers. These values are not probabilities themselves; rather, the probability of an outcome is determined by the absolute square (the Born Rule), requiring the state to be normalized:
\[|\alpha|^2 + |\beta|^2 = 1\]
For a fair coin where the outcomes are equiprobable, the amplitudes are defined as \(1/\sqrt{2}\) (ignoring the complex phase), since:
\[P(H) = \left| \frac{1}{\sqrt{2}} \right|^2 = \frac{1}{2}\]
In Hilbert space, exchanging two identical particles corresponds to a transformation of the state:
For fermions: \[\psi(x_1, x_2) = -\psi(x_2, x_1)\]
For bosons: \[\psi(x_1, x_2) = +\psi(x_2, x_1)\]
For fermions, this antisymmetry implies: \[\psi(x,x) = 0\]
This is the Pauli exclusion principle: no two identical fermions can occupy the same quantum state.
For bosons, symmetric states allow multiple occupation. Any number of photons, for example, can occupy the same state. This enables phenomena such as Bose–Einstein condensation.
Particles do not possess classical individuality.
Consider a parabolic mirror. A photon emitted from the focal point is later detected on a screen after reflecting from the mirror. Classically, one would imagine the photon taking a specific path: leaving the source, reflecting at a definite point, and arriving at the detector.
However, the photon is not assigned a single trajectory. Instead, it can be shown that it takes all the possible paths. Contributions from the entire surface of the mirror determine where the particle most likely hits the screen.
Quantum systems can exhibit behavior that has no classical analogue. A particle encountering a potential barrier higher than its energy can still be detected on the other side.
This phenomenon, known as tunneling, does not imply that the particle travels through the barrier in the classical sense. The wavefunction simply has nonzero amplitude across the barrier, and measurement may yield a detection beyond it.
In this sense, it is not meaningful to ask how the particle “passed through” the barrier, or how long it spent inside it. The formalism provides probabilities of outcomes, not trajectories of individual objects.
This reinforces the idea that quantum particles are not persistent entities following well-defined paths, but manifestations of an underlying informational structure.
A plane wave: \[\psi(x) = e^{ikx}\] has a well-defined momentum but is completely delocalized.
To localize a particle, one must superpose many momenta: \[\psi(x) = \int a(k) e^{ikx} \, dk\]
The more localized the position, the broader the momentum distribution. This is expressed by the uncertainty principle: \[\Delta x \Delta p \ge \frac{\hbar}{2}.\]
Heisenberg imagined trying to pinpoint the exact location of an electron by illuminating it with a photon. To see the electron more clearly, one needs a photon with a very short wavelength (high energy), like a gamma ray. However, a high-energy photon acts like a billiard ball; the moment it hits the electron to reveal its position, it delivers a massive kick of momentum, sending the electron flying off in an unpredictable direction. If one uses a lower-energy photon to avoid disturbing the electron, the long wavelength becomes too blurry to resolve the position. Heisenberg realized that the act of measurement itself imposes a fundamental limit: the more you sharpen your vision of where a particle is, the more you blur its path.
It would be easy to think that the uncertainty is just the problem of observation and that particles would actually have both well defined position and momentum, simultaneously. However, this is not the case.
Consider a single particle in a vast space. Its wavefunction is a pure sine wave. Its energy is \(E=hf\) where \(f\) is frequency. Its probability is perfectly flat. Because space is so huge, the chance of finding the particle at any one specific point is practically zero. In this state, the particle’s position is totally smeared out—it simply doesn’t have a specific ’here’ or ’there’. The only way to localize the particle is to stack additional waves into the wavefunction. These waves interfere with each other, canceling out in most places and peaking in one small spot. But then you are mixing multiple energies together. The more you pin down the position, the more the energy ’smears.’ The fuzziness isn’t a measurement error; it’s just how waves work.
It’s like a musical note: you can have a pure, steady pitch that lasts forever (perfect energy, no timing), or you can have a short, sharp ’staccato’ pop (perfect timing, no pitch). You physically cannot have both at once.
Composite systems can exhibit correlations that cannot be reduced to their parts. These correlations violate classical locality constraints, as demonstrated by Bell-type inequalities.
For example: \[|\Psi\rangle = \frac{1}{\sqrt{2}} \left( | \uparrow \downarrow \rangle - | \downarrow \uparrow \rangle \right)\]
This state cannot be written as a product of individual states. The system must be described as a whole.
Entanglement is a defining feature of quantum mechanics, linking subsystems into a single, inseparable structure.
Composite systems can exhibit properties not present in their constituents.
An atom composed of an even number of fermions behaves as a boson, while one with an odd number behaves as a fermion. This affects how collections of such atoms behave statistically.
Bosonic atoms can occupy the same quantum state, leading to macroscopic quantum phenomena such as Bose–Einstein condensation.
This is a clear example of emergence: collective behavior obeys new rules not evident at the microscopic level.
When quantum mechanics is combined with special relativity, the natural framework becomes quantum field theory.
In QFT, fields—not particles—are fundamental. Every point in space is associated with field values. Particles appear as excitations of these fields.
A useful analogy is a continuous medium composed of coupled oscillators. Disturbances propagate as waves, and quantized excitations are observed as particles.
For a scalar field \(\phi(x)\), the energy density may take the form: \[\mathcal{H} = \frac{1}{2} \Pi^2 + \frac{1}{2} (\nabla \phi)^2 + \frac{1}{2} m^2 \phi^2\]
Different fields correspond to different particles. Interactions arise from couplings between fields.
This framework is extraordinarily successful—provided spacetime itself remains fixed.
Quantum mechanics suffers the so-called measurement problem. QM describes a superposition of possibilities, yet observations yield definite outcomes. Particles are in all possible states, such as here and there - simulatenously, until observed.
What constitutes an “observer”?
Different interpretations offer different answers:
Copenhagen: measurement introduces classical outcomes via so-called “collapse of the wavefunction”
Many-Worlds: all outcomes occur in branching states
Objective collapse: wavefunction collapse is physical
Relational / information-based: states are observer-dependent
The formalism itself does not uniquely define what an observer is.
A modern operational view is that an observer is any system that produces a stable record of information through interaction.
(TODO: Need to hypothetize whether my wife meets the criteria of being a stable records of information. That is a brave hypothesis to test! Proceed with extreme caution—that particular variable has a reputation for being highly volatile, regardless of what the laws of physics might suggest!)
When a system interacts with an environment, entanglement spreads information across many degrees of freedom.
At the level of the full system, evolution remains unitary. However, when one considers only a subsystem, information appears to be lost.
This is captured by the reduced density matrix: \[\rho_S = \mathrm{Tr}_E(\rho_{SE})\]
Interactions with the environment suppress interference terms—a process known as decoherence.
Entropy of the subsystem increases: \[S(\rho) = -\mathrm{Tr}(\rho \log \rho)\]
Information becomes distributed into many inaccessible degrees of freedom. Reversing this process would require control over an enormous number of variables.
Thus, irreversibility emerges not as a fundamental law, but as a practical consequence of complexity.
An “observer,” in this sense, is a system that participates in such irreversible encoding of information.
What is the system we have described here?
Quantum Mechanics is often regarded as the most accurate theory we have. Once we know the amplitude and phase of a particle’s wavefunction, we can predict its future evolution with astonishing precision. Particles appear quite trivial as classes with only a couple of attributes, plus the wavefunction that contains all the information about the system.
Since we want to begin with the material taught in a first QM course, let us start with a minimal single-particle description. This is not QFT yet, but it is a useful stepping stone.
class Particle {
double mass; // Rest mass
double charge; // Coupling to electromagnetic field
double spin; // 0, 0.5, 1.0 etc.
Wavefunction wavefunction; // Superposition of modes
Vector3 getExpectedPosition(double time) {
// Compute center-of-mass from interference pattern
}
};The wavefunction is a superposition of modes. Each mode is essentially a complex exponential (plane wave) characterized by wavenumber and phase.
The first approach (momentum primary) aligns well with physics textbooks:
class Mode {
Vector3 k; // Wavenumber, p = \hbar k
double amplitude; // Complex coefficient magnitude & phase can be combined
double phase; // Initial phase offset
double frequency() {
// Natural units: h = c = 1
return k.squaredNorm() / 2m; // $\omega = \frac{k^2}{2m}$
}
};The wavefunction is then \(\Psi(\mathbf{x}, t) = \sum_i c_i \exp(i(\mathbf{k}_i \cdot \mathbf{x} - \omega_i t))\), or in the continuum limit an integral. A single mode is completely delocalized. As we so intuitively explained it in the previous chapter, localization arises from interference of many modes forming a wave packet.
Wavefunction createWavePacket(Vector3 center, Vector3 width) {
// Sum many k-modes with Gaussian envelope in momentum space
}Position is not a fundamental attribute of the Particle.
It emerges as the expectation value: \[\langle \mathbf{x} \rangle = \int
\Psi^*(\mathbf{x}) \mathbf{x} \Psi(\mathbf{x}) \, d^3x\]
Unfortunately, this intuitive single-particle description already fails for high energies (pair production, variable particle number) and does not incorporate special relativity properly. But we insisted to design the particle class to serve as a pedagogical starting point only.
In order to switch to QFT we must abandon the single-particle picture. According to quantum field theory, the fundamental entities are fields that exist everywhere. Particles are localized excitations (quanta) of these fields. Unlike a classical field, a quantum field is operator-valued and capable of creating or annihilating particle excitations. To simulate the Standard Model we need multiple fields, one for each fundamental degree of freedom (with appropriate spin and gauge representation).
The true conceptual jump from ordinary quantum mechanics to quantum field theory is not relativity alone. It is the abandonment of fixed particle number.
In introductory QM, one typically studies a wavefunction describing exactly one particle: \[\Psi(\mathbf{x}, t)\] or perhaps a fixed number of particles: \[\Psi(\mathbf{x}_1, \mathbf{x}_2, \dots, \mathbf{x}_N, t)\]
The number of particles is assumed from the beginning and never changes. This works remarkably well for low-energy systems such as atoms, molecules, and condensed matter systems.
However, at sufficiently high energies, nature does not respect this restriction. Particles can be created, annihilated, or transformed into entirely different particles: \[\gamma \rightarrow e^- + e^+\] \[e^- + e^+ \rightarrow \gamma + \gamma\]
A fixed-particle Hilbert space is therefore no longer sufficient. We need a framework capable of describing states with arbitrary particle number.
This leads to the idea of second quantization.
Instead of tracking individual particles directly, QFT tracks the occupation of field modes.
For each momentum mode \(\mathbf{k}\), we associate an occupation number: \[n_{\mathbf{k}} = 0,1,2,\dots\]
A quantum state is then described by listing how many quanta occupy each mode: \[|n_{\mathbf{k}_1}, n_{\mathbf{k}_2}, n_{\mathbf{k}_3}, \dots \rangle\]
This is called a Fock state.
The vacuum state contains no particles at all: \[|0\rangle\]
A single-particle excitation with momentum \(\mathbf{k}\) is created by applying a creation operator: \[a^\dagger(\mathbf{k}) |0\rangle\]
Two identical bosons in the same mode: \[\frac{(a^\dagger(\mathbf{k}))^2}{\sqrt{2!}} |0\rangle\]
The operators satisfy algebraic rules encoding quantum statistics.
For bosons: \[[a(\mathbf{k}), a^\dagger(\mathbf{k}')] = \delta^{(3)}(\mathbf{k}-\mathbf{k}')\]
For fermions: \[\{a(\mathbf{k}), a^\dagger(\mathbf{k}')\} = \delta^{(3)}(\mathbf{k}-\mathbf{k}')\]
The fermionic anticommutation relation automatically produces the Pauli exclusion principle: \[(a^\dagger)^2 = 0\]
Meaning that two identical fermions cannot occupy the same quantum state.
The quantum field itself is no longer an ordinary function. It becomes an operator-valued object: \[\hat{\phi}(x)\]
Roughly speaking, the field operator is built from all creation and annihilation modes: \[\hat{\phi}(x) = \int \frac{d^3k}{(2\pi)^3} \left( a(\mathbf{k}) e^{-ikx} + a^\dagger(\mathbf{k}) e^{ikx} \right)\]
This expression is enormously important conceptually.
The annihilation operator removes a particle from a momentum mode. The creation operator adds one. The field therefore becomes a machine capable of changing particle number dynamically.
In this sense, particles are no longer fundamental objects. They are excitations generated by the field operators acting on the vacuum.
In ordinary QM, one could imagine the wavefunction as a single object being updated over time.
In QFT, the architecture changes completely.
The system now resembles:
a potentially infinite collection of oscillatory modes,
a shared vacuum state,
and operators that modify the occupation of those modes.
Conceptually, the theory behaves less like a simulation of individual particles and more like a distributed state machine operating on an infinite-dimensional Hilbert space.
The familiar “particle” picture survives only as an approximation valid when localized excitations behave independently.
In the free theory, a quantum field in momentum space is equivalent to a set of harmonic oscillators, one per momentum mode.
class QuantumField {
const double m; // Mass of quanta of this field
// In practice: continuous or discretized over a box
std::map<Vector3, QuantumOscillator> modes; // or FFT-based grid
void createParticle(Vector3 k, double amplitude = 1.0) {
modes[k].n++; // Apply creation operator
// In full QFT this acts on the Fock state
}
};In QM the Position is an output (an eigenvalue/observable). In QFT, fields are defined over spacetime coordinates, so spacetime labels become part of the field definition itself. A Field is essentially a std::vector or grid where the index is the position \(x\), and the value at that index is the field strength \(\phi(x)\).
The Standard Model uses Minkowski Space. Technically, this is a vacuum solution to the Einstein field equations of General Relativity where the energy-momentum tensor is zero. It describes a flat, four-dimensional manifold where time and space are woven into a single fabric with Lorentzian metric signature of \((-+++)\) rather than the Euclidean \((++++)\) metric. It is a trivial, hardly worth mentioning, really. We’ll get back to the actual curvature and gravity mess once we get the basic physics engine running without crashing. For now, just assume the “position” is a point on this manifold described by a Four-Vector:
\[x^\mu = (ct, x, y, z)\]
When a new particle is created, we just increment the field counter. However, this is not quite right. A realistic implementation needs creation and annihilation operators \(a^\dagger(\mathbf{k})\), \(a(\mathbf{k})\) satisfying the appropriate commutation (bosons) or anticommutation (fermions) relations, acting on the Fock vacuum \(|0\rangle\). No big deal either.
Now that we have Field class, one might expect that the universe could be composed as an array of fields. However, the fields are not all alike, several different field classes are needed (with the correct Lorentz transformation properties).
class Universe {
// Middleware for mass generation
HiggsField backgroundField;
// Fermion sectors (The 'Legacy' code that was copy-pasted 3 times)
Generation firstGen {Electron, UpQuark, DownQuark, ElectronNeutrino};
Generation secondGen {Muon, CharmQuark, StrangeQuark, MuonNeutrino};
Generation thirdGen {Tau, TopQuark, BottomQuark, TauNeutrino};
// Gauge Bosons (The 'Communication Protocol' handlers)
GluonField strongForce; // SU(3)
W_Z_Fields weakForce; // SU(2)
PhotonField emForce; // U(1)
};Each field carries its own quantum numbers (representations under the gauge group \(U(1)_Y \times SU(2)_L \times SU(3)_c\)). Interactions arise from coupling terms in the Lagrangian (Yukawa, gauge covariant derivatives, etc.), not from manually checking wave overlap.
When a field excitation interacts with a macroscopic detector, the delocalized state becomes entangled with the environment. From the observer’s perspective this appears as a “collapse” to a definite outcome, with probability given by \(|\Psi(x)|^2\) (Born rule).
In a full relativistic QFT treatment one must be careful with causality and avoid instantaneous collapse. One can’t have information traveling faster than the speed of light.
The local phase of a field’s wavefunction can change at any point. To maintain physical consistency, one must then introduce a new field to compensate for these local shifts.
The Logic: If we want the freedom to rotate the Electron phase locally (\(U(1)\) symmetry), we are forced to include a Photon field to handle the differences.
The Result: Interaction isn’t a feature we manually add; it is a constraint required by the symmetry.
| Symmetry Group | Gauge Fields | Physical Bosons |
|---|---|---|
| \(U(1)_Y\) | \(B_\mu\) | mixes into Photon and \(Z\) |
| \(SU(2)_L\) | \(W^1_\mu, W^2_\mu, W^3_\mu\) | \(W^\pm\) and part of \(Z\) |
| \(SU(3)_c\) | \(G^a_\mu\) | Gluons |
Starting from the familiar single-particle QM class, we have gradually refactored our worldview toward fields and created an illusion of understanding.
While the free-field oscillator picture is surprisingly clean—a coupled oscillator degree of freedom across space—the transition to a professional-grade understanding of the Standard Model involves surmounting quite massive hurdles.
When an electron moves, it is constantly emitting and reabsorbing virtual photons, which in turn split into virtual electron-positron pairs. If one tries to calculate the mass or charge of an electron by summing up all these possible sub-processes, the math returns infinity. This is because the "bare" parameters in the Lagrangian don’t account for the fact that the particle is constantly "clothed" by its own interaction field. Mastering these requires learning Renormalization Group (RG) Flow, where one must understand how coupling constants change depending on the energy scale, to cancel them out.
Then there is Non-Abelian Overhead. While \(U(1)\) (electromagnetism) is relatively straightforward, the \(SU(3)\) of the Strong Force introduces self-interactions. The gluons (the message brokers) carry charge themselves, leading to a non-linear, recursive mess that is extremely difficult to solve. One also must move between the operator formalism (the "Imperative" approach) and the Feynman Path Integral (the "Functional" approach, essentially a Monte Carlo simulation over every possible history). Calculating a single interaction often requires summing over an infinite number of possible execution paths for the particles involved.
A famous remark often attributed to Stephen Hawking: “The Standard Model is a set of equations that we can write on a T-shirt, but it is not very beautiful.” Is this really the best the universe has to offer?
The quote fits so well. It highlights the "Spaghetti Code" nature of the Standard Model. It works perfectly, but it feels like it was written by a developer who was in a hurry and kept adding global variables (weakIsospin, hypercharge, colorCharge) to fix bugs. Maybe the original architect left without writing any documentation, and now the junior developers are just patching things as they go.
Boss, the particles aren’t staying together!
Just throw in a StrongForce patch and a few colorCharge flags!
General relativity does not concern itself with observations. The universe exists with or without intelligent, conscious observers. As far as general relativity is concerned, observers are no different from rocks. A psychosocially complex, traumatized, and poorly maintained human falling into a black hole is treated no differently from a rock of the exact same mass.
Yet, like quantum mechanics, this theory demands a profound departure from classical intuition. To understand how it works, we have to look at the very fabric of the cosmos.
For a programmer, transitioning from classical physics to General Relativity is like moving from writing simple application code to rewriting the operating system’s memory management.
While Quantum Field Theory (QFT) deals with the “values” inside the cells of the universe, General Relativity (GR) defines the “distance” between those cells and the rules for traversing them. Mathematically, we model this universe as a four-dimensional differentiable manifold \(\mathcal{M}\) equipped with a metric tensor \(g_{\mu\nu}\).
The metric determines distances, time intervals, angles, and the causal structure of reality. The infinitesimal spacetime interval is given by: \[ds^2 = g_{\mu\nu} \, dx^\mu dx^\nu.\]
This single, elegant geometric object entirely replaces the Newtonian gravitational potential, absolute space, and absolute time. Crucially, the metric is not a passive background grid; it is dynamic. Spacetime geometry actively responds to the distribution of matter and energy.
The so-called Equivalence Principle states that inertial mass and gravitational mass are identical. In Newtonian mechanics, a falling object accelerates because a physical force pulls on it. In General Relativity, no force acts at all.
Instead, the particle is simply trying to move in a straight line, or “follow its nose” through a curved environment. It follows a geodesic: \[\frac{d^2 x^\mu}{d\tau^2} + \Gamma^\mu_{\nu\rho} \frac{dx^\nu}{d\tau} \frac{dx^\rho}{d\tau} = 0,\] where \(\Gamma^\mu_{\nu\rho}\) represents the Christoffel symbols constructed from the metric.
This equation is the ultimate lazy-evaluation algorithm: it describes pure, unforced inertial motion. Gravity disappears locally. What we perceive as gravitational attraction is just nearby geodesics naturally converging in curved space.
The curvature of spacetime is encoded in the Riemann curvature tensor: \[R^\mu_{\;\nu\rho\sigma}.\] It measures the failure of vectors to return unchanged after parallel transport around infinitesimal loops. Contractions of the Riemann tensor yield the Ricci tensor \(R_{\mu\nu}\) and the Ricci scalar \(R\), which summarize the curvature relevant to volume distortion and geodesic convergence.
While the Ricci tensor describes how matter locally curves spacetime, it does not tell the whole story. The Riemann tensor can be decomposed into the Ricci curvature, which vanishes in a vacuum, and the Weyl curvature, which does not. The Weyl tensor is responsible for tidal forces and allows gravitational influence to propagate through the vacuum of space as gravitational waves (not again, nature waves!)
The most intuitive way to understand the Ricci scalar (also known as the scalar curvature, denoted as \(R\) without tensor subscripts) is to think of it as a measures how much the volume of a region in curved space deviates from a flat, Euclidean space.
The dynamics of this geometry are governed by the famous Einstein field equations: \[G_{\mu\nu} = 8\pi G \, T_{\mu\nu},\] where \(G_{\mu\nu}\) is the Einstein tensor: \[G_{\mu\nu} = R_{\mu\nu} - \frac{1}{2} g_{\mu\nu} R,\] and \(T_{\mu\nu}\) is the stress–energy tensor, which encodes energy density, momentum density, pressure, and shear stress.
These equations equate geometry with matter. As the physicist John Wheeler famously summarized: Spacetime tells matter how to move. Matter tells spacetime how to curve.
A profound mathematical feature of these equations is the contracted Bianchi identity. It states that the covariant divergence of the Einstein tensor vanishes identically: \[\nabla^\mu G_{\mu\nu} = 0.\] Because the field equations equate \(G_{\mu\nu}\) with the stress–energy tensor \(T_{\mu\nu}\), this identity mathematically forces the local conservation of energy and momentum: \[\nabla^\mu T_{\mu\nu} = 0.\] Conservation of energy isn’t an extra rule programmed into the universe; it is a logical consequence of the geometry itself.
Because the metric \(g_{\mu\nu}\) varies depending on where you are and how much mass is around, time itself is geometry-dependent. For a stationary observer: \[d\tau = \sqrt{-g_{00}} \, dt.\] Clocks at different gravitational potentials tick at different rates. This means time is not a global, absolute clock. It is, in fact, a deeply personal issue.
To demonstrate this, let us imagine an average programmer in a safe orbit around a black hole. As a thought experiment, we will consider the scenario of the programmer pushing his wife into the black hole. While this is undoubtedly a terrible thing to do, it serves as an excellent scientific test—provided we keep in mind that it is purely hypothetical, and not a recommendation.
The closer the falling wife gets to the event horizon, the slower she appears to fall from her husband’s perspective. To him, she will never actually seem to cross it. A distant husband would have to wait an infinite amount of time to watch his wife pass the point of no return.
Things look very different from the wife’s point of view (my wife’s response: “As usual!”). For her, there is no dramatic physical boundary at the event horizon. Her watch keeps ticking normally. As she falls, she can look back and see the light from the outside universe perfectly well. Because of gravitational blueshift and time dilation, the outside universe appears sped up and energetic. Yet, because she is falling so quickly, she has only a limited proper time—seconds or minutes—before hitting the singularity. She crosses the horizon smoothly, seeing only a finite slice of the universe’s future, and meets her doom inside.
Black holes eventually evaporate via Hawking radiation. Since the husband sees his wife take “infinite time” to cross the horizon, and the black hole will eventually evaporate in a finite (albeit unimaginably long) time, does the black hole disappear before she even crosses it?
While classical relativity says she crosses the horizon in mere seconds of her own time without seeing the end of the universe, quantum mechanics introduces a massive paradox. Because a distant observer sees the black hole evaporate over trillions of years, all the information about the falling observer must eventually be radiated back out.
To resolve this clash of perspectives, some physicists argue that the horizon isn’t a peaceful gateway at all, but a raging “firewall” of quantum energy that would vaporize the wife the moment she touched it. Who is right? Einstein or the quantum physicists? Currently, we don’t know—and that is the exciting frontier.
Of course, surviving such a trip is strictly the domain of science fiction. Fierce tidal forces would “spaghettify” and tear any observer apart. The programmer’s wife would also get burned quite badly - receive a lethal, highly boosted cosmic sunburn as a parting gift. On the bright side, she would find her husband aging rapidly relative to her—if that is any consolation!
Unlike quantum mechanics, which is a theory of states evolving tick-by-tick in time, General Relativity is a theory of consistent four-dimensional configurations.
Given suitable boundary conditions, the Einstein equations constrain the allowed geometries of the entire cosmos. Time evolution is not fundamental; it is simply a human slicing of a four-dimensional structure. The equations are elliptic-hyperbolic constraints on geometry. This is why the initial value problem is so subtle, global solutions are rare, and exact solutions are highly symmetric. Spacetime is not computed step-by-step; it exists as a self-consistent, static whole.
This suggests that we live in a static Block Universe. The falling observer and the frozen observer are both real; they are simply viewing the same static, 4D geometric structure from different perspectives. The past, the present, and the future all exist simultaneously as the geometry of four-dimensional spacetime. Change is an illusion of the observer; reality is simply the geometry of the whole.
There are cracks even in the most beautiful stained-glass window of physics.
General Relativity tells us that gravity isn’t a force, but the shape of the container. However, it describes the behavior of the container without explaining the fabric of the container itself.
Astronomers have found numerous black holes, but physics remains painfully silent about the physical singularity at their core. This is not a mere coordinate glitch, but a point of ultimate physical breakdown: a place where all of the matter from a collapsed star (say, ten times the mass of our Sun) is crushed down into a region of literally zero radius (\(r = 0\)). This forces the density and the curvature of spacetime to become infinite (\(\rho \rightarrow \infty\), \(R \rightarrow \infty\)), causing our mathematical manifold description to completely crash.
The theory does not fail mathematically; it predicts its own domain of invalidity. Our only saving grace is the “cosmic censorship” hypothesis, which states that nature is hiding these embarrassing mathematical breakdowns behind the privacy of an event horizon.
Furthermore, GR treats spacetime as a perfectly smooth manifold. This is a beautiful abstraction that works flawlessly until we zoom in to the Planck scale—the threshold where the smooth geometry of General Relativity collides with the discrete, pixelated fluctuations of Quantum Mechanics.
This fundamental clash is the main reason we know Einstein’s theory of gravity, brilliant as it is, cannot be the final word.
In the QFT implementation chapter, we briefly touched on GR, since space and time are the necessary background that QFT needs to define its fields. In truth, downplaying GR as ’no big deal’ wasn’t entirely fair.
Anyone familiar with GR most likely laughed while reading that—or perhaps cried, or more likely both.
To get any sense out of GR, let’s implement it.
In a rigorous simulation of General Relativity, we do not store forces or gravitational fields. We store the Metric Tensor (\(g_{\mu\nu}\)), which acts as our spatial lookup table.
/**
* @brief Represents a local patch of the 4D Manifold.
*/
class SpacetimeCell {
public:
// The Metric Tensor: 10 independent components (symmetric 4x4)
// This is the ONLY fundamental state variable of geometry.
double g[4][4];
// The Christoffel Symbols (Gamma) and Riemann Curvature are NOT state variables.
// They are computed on-the-fly (or cached) from the first and second
// derivatives of the metric 'g'.
// They represent the "bending" of the memory buffer.
GammaTensor calculateChristoffel() const;
RiemannTensor calculateRiemann() const;
/**
* @brief The Geodesic Equation (The Equation of Motion)
* There is no 'force' or 'acceleration' variable in the universe's physics engine.
* The next state is determined purely by local pointer arithmetic (the Christoffel symbols).
*/
Vector4 computeGeodesicStep(Vector4 velocity, double d_tau) {
Vector4 acceleration = {0, 0, 0, 0};
auto Gamma = this->calculateChristoffel();
// Classic Einstein summation wrapped in a nested loop.
// It computes how the grid coordinates "bend" the velocity vector.
for (int mu = 0; mu < 4; mu++) {
for (int nu = 0; nu < 4; nu++) {
for (int rho = 0; rho < 4; rho++) {
acceleration[mu] -= Gamma[mu][nu][rho] * velocity[nu] * velocity[rho];
}
}
}
// Update velocity and position using Euler integration over proper time step d_tau
return velocity + (acceleration * d_tau);
}
};Now let’s compare this to our implementation of Quantum Field Theory.
In the grand hierarchy of the universal source code, it is clear that while the Standard Model was written by a committee of panicked, underpaid junior developers working on a Friday afternoon, General Relativity was designed by a single Senior Architect during a moment of pure, uninterrupted clarity.
Compared to the cluttered, variable-heavy spaghetti code of QFT—with its arbitrary coupling constants, messy exclusion rules, and infinite loops that require "renormalization" hacks just to keep the compiler from crashing—General Relativity is architecturally superior in every way.
The architect responsible for this module surely deserves a raise. They managed to replace a thousand localized, hardcoded force functions with a single, elegant system of pointer arithmetic. In GR, "gravity" is not an active thread running in the background; it is simply a consequence of the fact that the memory addresses themselves are curved. It is a theory that doesn’t just work; it performs with a level of mathematical grace that makes the rest of physics look like a legacy bug-fix.
However, there is a catch.
In our simple SpacetimeCell above, we assumed the metric
\(g\) was a read-only, static
background. But the true, mind-bending complexity of GR is that the
database writes back to itself.
The matter-energy values of QFT (the Stress-Energy Tensor, \(T_{\mu\nu}\)) act as write-commands to the Metric (\(g_{\mu\nu}\)). As matter moves, it mutates the metric. As the metric mutates, it changes the geodesic paths, which forces the matter to move differently. This creates a highly non-linear, self-referential loop. In software terms, it is a recursive function where the stack frame itself is constantly warping while the function executes.
Awesome. we’ll just write a quick Runge-Kutta integrator, set up a 4D grid, write a finite-difference stencil for the Einstein Field Equations, and simulate a binary black hole merger by next weekend.
If there is one universal law of software engineering, it is this: Do not roll your own cryptography, and do not roll your own General Relativity solvers.
While the core equation of GR (\(G_{\mu\nu} = \frac{8\pi G}{c^4} T_{\mu\nu}\)) looks deceptively simple, expanding it yields a system of ten coupled, highly non-linear, hyperbolic-elliptic partial differential equations. Written out in full, a single equation can span pages.
If you try to write a naive solver, your simulation will face-plant into several classic software-engineering traps:
Coordinate Singularities (The Div-by-Zero Bug):
If you use standard coordinates (like Schwarzschild coordinates) near a
black hole event horizon, your metric components (\(g_{00}\) and \(g_{rr}\)) will diverge to infinity. Your
simulation will crash with a NaN or overflow error.
Resolving this requires advanced mathematical coordinate transformations
(like Kruskal-Szekeres coordinates or "moving puncture" gauge
conditions) just to keep the grid mathematically stable.
Constraint Violations (Memory Corruption): The Einstein equations are split into "evolution equations" (which update the grid over time) and "constraint equations" (which must remain true at every single step, like \(\text{div}(B) = 0\) in electromagnetism). In a naive simulation, numerical rounding errors will accumulate. Within a few frames, your constraint equations will fail, meaning your spacetime grid has physically corrupted itself.
Extreme Scale (High Performance Computing): To resolve the high-frequency gravitational waves radiating from a binary merger, you need Adaptive Mesh Refinement (AMR). Writing a dynamically scaling, parallelized 4D grid that runs efficiently across thousands of GPU nodes is a multi-decade software engineering challenge.
Fortunately, the open-source community has already built the frameworks so we don’t have to. We can use the industry-standard, production-ready engines:
The Einstein Toolkit: The Kubernetes of numerical relativity. It is a massive, community-driven, high-performance computing framework built on the Cactus infrastructure. It handles everything from the 3+1 spacetime decomposition to adaptive mesh refinement and relativistic hydrodynamics.
NRPy+ (Python-based Code Generation): A brilliant Python package that uses SymPy to let you write your physics equations in clean, high-level Einstein notation. It then compiles those equations into highly optimized, SIMD-parallelized C++ code. It is designed to lower the barrier to entry, letting you run numerical relativity on a standard laptop.
OGRePy / xAct / SageManifolds: If you don’t need a full-blown dynamic simulation and just want to do symbolic tensor algebra (e.g., calculating Christoffel symbols, Riemann curvature, or geodesics from a given metric), do not do the derivatives by hand.
General Relativity tells us that the reality of an event depends entirely on the metric of the observer. There is no objective time in which the fall happens; there is only the geometric relationship between the worldlines. The beauty of GR lies in this consistency. The math never breaks; it only redefines the relationship between the observer and the observed.
This suggests that we live in a static Block Universe. The falling observer and the frozen observer are both real; they are simply viewing the same static, 4D geometric structure from different perspectives. The past, the present, and the future all exist as the geometry of four-dimensional spacetime.
A central paradigm in theoretical physics is the pursuit of grand unification: the formulation of a single mathematical framework capable of describing all physical phenomena. The primary obstacle—and the essential first step toward this ’Theory of Everything’—is the synthesis of General Relativity and Quantum Mechanics into a coherent theory of Quantum Gravity.
But the wheels start to fall off the wagon almost instantly when applying the rules of QFT to the curved metric \(g_{\mu\nu}\) of GR. In flat space, all inertial observers agree on the "vacuum" \(|0\rangle\). In curved space, this consensus evaporates.
Gravity stretches the field ripples. An observer in a stable region might see a vacuum, while an accelerating observer perceives a thermal bath of particles. This is the Unruh Effect, where the temperature \(T\) is proportional to acceleration \(a\): \[T = \frac{\hbar a}{2\pi c k_B}\]
If observers cannot agree on whether a particle exists, the very definition of a "particle" as a basic building block begins to crumble. The framework ceases to provide a globally consistent notion of particles or vacuum.
The most jarring illustration of the incompatibility between Quantum Field Theory (QFT) and General Relativity (GR) is the Cosmological Constant Problem.
In QFT, the vacuum is never truly empty. Each field mode contributes a zero-point energy \(\frac{1}{2}\hbar \omega\). Summing over all modes up to a cutoff frequency \(\omega_{max}\) gives a vacuum energy density
\[\rho_{vac} = \int_{0}^{\omega_{max}} \frac{1}{2} \hbar \omega \frac{d^3k}{(2\pi)^3} \propto \omega_{max}^4 .\]
If the cutoff is taken at the Planck scale, one obtains
\[\rho_{vac} \sim 10^{111} \text{ J/m}^3.\]
Astronomical observations of the accelerating expansion of the universe, however, imply
\[\rho_{obs} \approx 10^{-9} \text{ J/m}^3.\]
The discrepancy is roughly a factor of \(10^{120}\) — often described as the worst prediction in the history of physics.
Effects such as the Casimir effect confirm that vacuum fluctuations have measurable consequences. However, QFT only measures differences in vacuum energy. When coupled to gravity, the absolute vacuum energy should act as a cosmological constant and curve spacetime. Naively, the predicted energy density would curve the universe catastrophically. Yet observations show that the cosmological constant is extraordinarily small.
And if this wasn’t big problem enough, then there is the catastrophe of time, a cosmic crisis we foreshadowed in our chapters on quantum mechanics and general relativity.
In General Relativity, time is not an external parameter but part of its geometric structure. Space and time are interwoven, and their geometry is determined dynamically by the distribution of mass and energy. Objects trace world-lines through this geometry, and what we perceive as the present is a three-dimensional cross-section of a four-dimensional structure.
A common interpretation of General Relativity—the so-called block universe view—suggests that past, present, and future events all coexist within the spacetime manifold.
Quantum Mechanics offers a very different perspective. In quantum theory, physical systems are described by wavefunctions that encode all available information about their states. These wavefunctions evolve deterministically in time according to the Schrödinger equation.
Importantly, quantum mechanics does not render time itself indeterminate. Time remains an external parameter in standard formulations of quantum mechanics, unlike in General Relativity where it is part of the dynamical structure.
Drop General Relativity into a simulation and it breathes; the geometry ripples and reacts.
Drop Quantum Mechanics into a simulation and nothing happens.
One theory includes the clock; the other requires you to provide and wind it. This gap suggests that ’unifying’ them is not a matter of merging two lists of rules, but of reconciling two entirely different definitions of ’happening’.
And if we didn’t have enough problems already, there is an even more fundamental crisis looming. As observers, we are hard-coded to sense a simple, 3D Euclidean world.
But why? Why do we not instead experience reality as native inhabitants of a high-dimensional, complex-valued Hilbert space, perceiving ourselves as the wave-like entities we actually are?
If quantum mechanics is the fundamental truth of the universe, why does our conscious experience look like classical Einsteinian spacetime (\(3+1\) dimensions, localized particles, and smooth gravity) instead of a state vector drifting through Hilbert space?
\[|\Psi_{\text{universe}}\rangle = \sum_{i} c_i | \psi_i \rangle\]
Mathematically, Hilbert space is where the real action happens. If we have \(N\) particles, they don’t live in our cozy 3D space; they live in a \(3N\)-dimensional configuration space. When you factor in quantum states, the “state vector” of the entire universe, \(|\Psi\rangle\), is just a single point rotating in an almost infinitely high-dimensional Hilbert space.
Under this view, spacetime is an illusion. Our 3D space (plus 1D time) is just an emergent “projection” or a convenient holographic slice of this massive mathematical ocean. We are waves, not localized, “billiard ball” citizens of Einstein’s spacetime. We are insanely complex, highly entangled wavefunctions.
So, why don’t we feel like waves?
Quantum decoherence solves this problem—at least to some degree. As macroscopic objects (made of roughly \(10^{27}\) particles), we are constantly being bombarded by photons, air molecules, and cosmic dust. Every time an environmental particle bounces off us, it “measures” our position. This interaction leaks our quantum phase information into the environment, effectively destroying our coherence. The fragile, high-dimensional interference of our wavefunction gets washed out, leaving behind a seemingly classical, localized, and highly stressed psychosocial object in 3D space.
Another explanation comes from entanglement (the idea that gravity is fundamentally quantum). The AdS/CFT holographic correspondence and the \(ER=EPR\) conjecture suggest that spacetime geometry is actually knitted together by quantum entanglement in Hilbert space. If you were to disentangle two regions of Hilbert space, the physical space between them would literally tear apart and grow infinite. Under this framework, we experience “Einstein” (spacetime and gravity) because gravity is just the thermodynamic, macroscopic manifestation of microscopic entanglement in Hilbert space.
But these are just technical explanations for why the universe behaves classically at the macroscopic scale. They don’t quite ease the existential itch.
Why Einstein? Why not Hilbert?
Logic and mathematics are abstract by nature. What is common to the addition of two bananas and the addition of two apples is the expression \(2+2\). Yet \(2+2\) is not something one can eat, touch, or weigh. It is not located anywhere in space. It has no mass, no electric charge. It cannot be detected with any measurement device—not even LIGO or the James Webb Space Telescope (JWST)! What, then, is it?
The most striking feature of mathematics is its stubborn universality. Two sentient beings, separated by light-years of vacuum or centuries of history, will inevitably converge upon the same Prime Number Theorem. No matter how far we look in space and time, all of physics appears to follow the same universal rules, without exception.
This suggests that mathematics is not a mere cultural artifact like music or fashion, but a reflection of a fundamental structure.
The physicist Eugene Wigner famously called this the “Unreasonable Effectiveness of Mathematics in the Natural Sciences.” Math does not appear to be just a language we speak, but a landscape we explore.
In the history of philosophy, several primary “doctrines” have attempted to explain this phenomenon.
Platonists argue that mathematical entities (numbers, sets, functions) are real, abstract objects that exist independently of us. They don’t exist in space or time, but they have a permanent existence in a “Platonic realm.”
The “unreasonable effectiveness” of mathematics in the physical sciences suggests that the universe is built on a mathematical blueprint. If we simply “made it up,” why does it predict the behavior of subatomic particles so perfectly?
Formalists, like David Hilbert, argue that mathematics is a formal game played with marks on paper. We agree on the results not because we’ve discovered some universal truth, but because we started with the same axioms (rules). If we both play chess with the exact same rules, we will both agree on what a checkmate looks like. That doesn’t mean checkmate is a fundamental law of physics; it is just the logical conclusion of the rules we agreed upon.
This school of thought argues that math is entirely a construction of the human mind. Mathematics appears universal only because the human brain evolved to process logic and patterns in a specific, advantageous way. We don’t see exceptions to math in the universe because we use math as the sensory filter to understand the universe in the first place. If something did not fit our mathematical logic, we might not even have the cognitive architecture to perceive it.
In this view, the universe may be fundamentally chaotic, and math is merely our brain’s formatting tool. Imagine if our eyes could only see red, green, and blue; we would confidently conclude the universe is made of only those colors. However, those colors are properties of us, the observers. Math could be a similar evolutionary filter, causing us to ignore the parts of reality that do not fit into tidy equations.
Structuralists argue that mathematics is about patterns and relationships, not the intrinsic nature of the objects themselves. Type theory formalizes this perspective: every object has a type, and operations are only valid if the types match. In programming, this is analogous to type-safe code: you cannot add a string to an integer without explicit type-casting or conversion.
Type theory serves as an alternative foundation for modern mathematics, bridging naturally to computer science, automated proof assistants, and functional programming.
One of the strongest arguments for Platonism is when math boldly leads the way and physical reality is forced to follow.
Astronomers didn’t find Neptune by aimlessly scanning the night sky. They noticed Uranus wasn’t moving the way Newton’s math said it should. Urbain Le Verrier did the pen-and-paper math, calculated the exact coordinates of an undiscovered gravitational disturber, and told observers where to look. They pointed a telescope there, and there it was.
Paul Dirac wrote down a relativistic quantum equation for the electron in 1928. The math stubbornly yielded two solutions (much like how \(\sqrt{4}\) can be \(2\) or \(-2\)). One solution described the standard electron; the other predicted a bizarre, positively charged twin. A few years later, the positron was physically discovered.
Einstein’s equations of General Relativity predicted that a sufficiently massive star could collapse into a spatial point of infinite density. Even Einstein found this physically absurd and assumed nature would prevent it. Yet, we now have direct images of event horizon boundaries thanks to the Event Horizon Telescope (EHT).
Mathematics is an axiomatic system. It consists of a set of axioms—statements assumed to be true without proof—and rules of logical inference used to generate further statements, called theorems.
Classical mathematics, from Euclid’s geometry to modern set theory, operates within such frameworks. One starts from a set of axioms, and mathematics is everything that logically follows.
Just like different physical theories have been unified, modern mathematics has undergone massive consolidation. In the early 20th century, it appeared that all disparate branches of math—from the smooth curves of geometry to the probabilities of statistics—could be expressed in the unified language of Set Theory. By defining a “number” or a “point” as a specific arrangement of sets, mathematicians created a universal assembly language.
As of today, Zermelo-Fraenkel Set Theory with the Axiom of Choice (ZFC) is the standard “assembly language” of mathematics. One can define a number as a set, a function as a set of ordered pairs, and a geometric shape as a set of points.
However, a growing rival is Category Theory. Where Set Theory focuses on the “insides” of objects (what elements are in a set), Category Theory focuses entirely on the “relationships” (how structures transform into one another). Many argue that Category Theory is a far more natural unified language because it handles compositional structures beautifully.
There is a surprisingly clean analogy between programming paradigms and the set-theoretic vs. category-theoretic perspectives. All software consists of two ingredients: data and code. Depending on which perspective you emphasize, you get different paradigms:
# Functional style (focus on code / transformations)
shift_left(integer)# Object-oriented style (focus on data / objects)
integer.shift_left()Set theory is analogous to the object-oriented, data-centric perspective: everything is built bottom-up from elements and sets of elements. Category theory is analogous to the functional, transformation-centric perspective: it focuses on how structures relate and compose, abstracting away the internal data.
In category theory, objects and morphisms (arrows) are central.
A simple example:
\[f: X \to Y, \quad g: Y \to Z \quad \Rightarrow \quad g \circ f: X \to Z\]
\(X, Y, Z\) are objects (which could be sets, spaces, types, etc.).
\(f, g\) are morphisms (functions, transformations).
\(g \circ f\) is the composed morphism, showing how the category-theoretic perspective emphasizes relationships and composition rather than internal content.
Modern mathematical philosophy has shifted significantly toward Mathematical Pluralism (Friend 2014). Proponents like Joel David Hamkins argue for a set-theoretic multiverse (Hamkins 2012), suggesting that instead of one absolute, unique mathematical reality, there exist diverse, distinct concepts of sets, each instantiated in its own valid mathematical universe (Priest 2024).
Pluralism allows multiple internally consistent mathematical worlds to coexist. Only a small subset of these frameworks appears realized in our specific physical universe, but multiple structures (set theory, category theory, type theory) remain fully valid within their own logical jurisdictions.
In computing, these ideas are highly practical: when building a compiler, a programming language, or an automated theorem prover, you must explicitly choose which underlying logic your system will enforce.
Not even mathematics is perfect.
David Hilbert famously dreamed of a universal, mechanical way to prove every mathematical truth. Later, researchers wondered if mathematical truth could be entirely mechanized as a computational process.
However, Kurt Gödel and Alan Turing shattered this dream of total mechanization. Turing proved that there are fundamental limits to what a machine can calculate, even given infinite time and memory. For example, Chaitin’s Constant \(\Omega\) is a well-defined real number that is mathematically proven to be uncomputable. Gödel proved that in any sufficiently powerful axiomatic system, there will always be true statements that the system’s own rules can never prove.
All mathematical doctrines attempt to resolve the same unsettling observation: the universal consensus of mathematical truth. Whether in the biological mind of a human or the silicon circuits of a space probe, the internal logic of mathematics remains invariant.
In computer science, there is no ambiguity that data-oriented and code-oriented programming paradigms serve as two complementary perspectives on the exact same underlying substrate—the Turing Machine.
However, this clean duality slightly breaks down when comparing set theory and category theory. Several deep puzzles remain:
The Continuum Hypothesis: Even if Set Theory (ZFC) is our standard assembly language, there are basic, intuitive questions it cannot answer. For example: Is there an infinity larger than the integers but smaller than the real numbers? ZFC’s formal answer is a shrug: “It is impossible to prove either way.”
Natural vs. Artificial Axioms: Formalism suggests we simply “make up rules”. But why do these specific rules map to physical reality so miraculously? This is the core of Wigner’s dilemma.
Logical Pluralism: If we alter classical rules—such as dropping the Law of the Excluded Middle (where a statement must be either true or false)—we get a completely different, yet mathematically consistent, universe. Why does our physical universe seem to heavily privilege classical logic?
There appears to be a repeating pattern: the deeper we look, the more slippery the target becomes. Can science actually unify anything?
When two theories of extraordinary precision (like General Relativity and Quantum Mechanics) stubbornly refuse to unify, the problem may not lie in either theory individually, but in the conceptual mathematical framework that contains them. They are expressions of fundamentally different mathematical worldviews. Their incompatibility may be signaling not a flaw in nature, but a limitation in the mathematical languages we have chosen to write our maps in.
One might ask whether entirely different kinds of universes could exist—ones that do not admit a description in terms of ordinary, classical mathematics.
If mathematics were merely a cultural game humans invented, could there be at least one person out of billions who could develop a functioning “non-mathematics”—a system that successfully describes observable physical measurements using an entirely different mathematical universe?
Actually, we don’t even need to look to other universes for this. Our own physics is already quietly pluralistic.
Does physics always have to follow standard, non-plural math? Absolutely not. A physical measurement—like a detector registering a photon—is just a raw event in the world. How we calculate and predict that event is entirely up to our choice of mathematical framework.
For instance, we standardly model quantum mechanics using complex numbers and continuous calculus. But we could stubbornly choose to describe the exact same quantum experiments using Constructive Mathematics (where infinite real numbers do not exist and the Law of the Excluded Middle is rejected), or even purely discrete graph theory and cellular automata.
The physics (the observable measurements) remains identical, but the mathematical ground beneath it shifts entirely.
So, a “non-mathematics” is not a system of chaos where \(2+2=5\). Rather, it appears to be the realization that we do not live in a single, rigid mathematical dictatorship. Physics does not demand a single “true” math; it is perfectly content to be mapped by a pluralistic multiverse of different logical systems. We are not discovering the one true language of the universe; we are simply choosing which mathematical dialect we prefer to write our maps in.
Across all major doctrines—Platonism, Formalism, Intuitionism, Structuralism, and Pluralism—one finds a common, unavoidable feature: mathematics is not arbitrary. Its universality and predictive power never fail to assert themselves to any rational observer, including average software developers suffering from ADHD.
However, to a software developer used to choosing the right tool for the job, the existence of Mathematical Pluralism strongly implies that Eugene Wigner’s “Unreasonable Effectiveness of Mathematics” may not be a divine, fundamental truth of the cosmos. Instead, it might just be that we have rummaged through an infinite toolbox of mathematical frameworks, found the one wrench that happens to turn our specific physical bolt, and declared it a miracle that it fits.
Modern biology has established that DNA is the blueprint of life, carrying the information required to build and maintain every known living organism. The path to this understanding has been gradual and cumulative.
In 1869, Friedrich Miescher isolated a previously unknown substance from white blood cells, which he called nuclein. This marked the first step toward identifying the molecular basis of heredity.
In 1888, Theodor Boveri observed thread-like structures during cell division, later named chromosomes. These structures were shown to carry hereditary information.
Thomas Hunt Morgan, working with fruit flies, linked specific traits to specific chromosomal regions. These regions became known as genes, establishing the physical basis of inheritance.
In 1928, Frederick Griffith’s experiment with Streptococcus pneumoniae demonstrated that a “transforming principle” could transfer hereditary traits between bacteria. This strongly suggested that heredity was encoded in a specific molecule.
The decisive breakthrough came in 1953, when James Watson and Francis Crick, building on X-ray diffraction data produced by Rosalind Franklin, revealed the double-helix structure of DNA. In 1958, the Meselson–Stahl experiment confirmed semi-conservative replication: each new DNA molecule contains one original strand and one newly synthesized strand. This explained how genetic information is reliably transmitted from cell to cell and generation to generation.
Over the past century, DNA has moved from hypothesis to direct manipulation. We sequence genomes, edit genes, and observe predictable biological consequences. The theory is not merely descriptive; it is operational and continuously verified in practice.
If DNA is the blueprint, regulatory genes determine how that blueprint is executed. All cells in a multicellular organism contain essentially the same genome, yet they differentiate into muscle, bone, skin, or neurons. The difference lies in gene regulation.
In the 1980s, Walter Gehring and colleagues discovered homeobox genes while studying fruit flies. One mutant developed a leg where an antenna should have been, revealing master regulatory genes that control body layout. These genes are remarkably conserved across species.
In a striking experiment, a gene responsible for eye development in mice was inserted into a fruit fly embryo. The fly developed additional, fully functional fly eyes—not mouse eyes. This demonstrated that the underlying genetic control mechanisms are deeply shared across species, supporting the common ancestry predicted by Charles Darwin.
Many of us software developers still have a lot of catching up to do when it comes to code reusability.
Applications in Everyday Life are numerous:
Medicine: Genetic testing, DNA sequencing, and gene therapy enable diagnosis and treatment at the molecular level. mRNA-based vaccines demonstrate direct practical use of genetic principles.
Forensics: Forensic DNA analysis reliably identifies individuals in criminal investigations.
Agriculture: Genetic engineering and DNA barcoding improve crops and track biodiversity.
Evolutionary biology: Molecular phylogenetics reconstructs evolutionary history with unprecedented precision.
When a gene is altered and a predicted change follows, the theory confirms itself in practice. Reality itself functions as an ongoing test of molecular biology.
Despite its complexity, DNA operates on remarkably simple principles. Its four nucleotides—adenine (A), thymine (T), cytosine (C), and guanine (G)—pair specifically (A with T, C with G). During replication, the two strands of the DNA double helix are separated, and each strand serves as a template. New complementary nucleotides are attracted to the exposed bases, guided by hydrogen bonds, forming two identical DNA molecules. In other words, the sequence of one strand determines the sequence of its partner, ensuring faithful duplication.
What is remarkable is that DNA is also fully digitizable, it can be coverted to binary string without loss of information. Entire genomes, including the human genome sequenced through the Human Genome Project, are stored and analyzed computationally. Advances in synthetic biology and genome synthesis allow scientists to construct functional genomes artificially and insert them into living cells.
At least for simple organisms such as bacteria, no additional “vital spark” (soul) is required. When the correct molecular structure is assembled and placed in the proper environment, the system behaves as a living organism.
The evidence that DNA is the blueprint of biological life is overwhelming. It encodes the structures that build cells, tissues, organs, and entire organisms. It governs development, reproduction, and adaptation.
Modern genetic science demonstrates something profound: biological information is real, measurable, manipulable, and predictive. Our ability to read, edit, and synthesize DNA shows that life operates according to structured informational principles.
Just as physical theories are no longer abstract descriptions detached from reality but continuously tested in practice, also in the case of DNA, reality itself functions as an ongoing confirmation. The living world—including beings capable of reflection and self-awareness—is built upon genetic information. DNA is therefore not merely associated with life; it appears to be the informational foundation from which complex, and possibly conscious, life are built.
Because DNA is essentially digital code, it inevitably raises a profound question: could we one day simulate our own existence and create virtual copies of ourselves?
Before diving into that thought experiment, we must acknowledge a serious objection.
According to Roger Penrose (Penrose 1989), the operation of the human brain might not be an axiomatic system. Gödel’s incompleteness theorem states that within any sufficiently powerful axiomatic system, there exist statements that are true but cannot be proven within that system.
Since computers and Turing Machines are equivalent to formal axiomatic systems, this implies that there are well-defined mathematical truths that no algorithm can ever compute. In other words, some problems are fundamentally uncomputable by any machine, regardless of its speed or memory.
Penrose speculates that the human brain can, at least in principle, apprehend such truths. If true, this suggests that human reasoning is not confined to algorithmic computation: the mind may access insights that no Turing machine can produce.
What Penrose effectively argues is that mathematics is more expansive than what a Turing machine is capable of describing. Even if the machine had an infinitely long tape and infinite time to run, it could not implement all of mathematics. If human consciousness resides on that ’far side’ of math, several consequences follow from this hypothesis:
Limits of Simulation: If the brain is non-algorithmic, then no digital computer, no matter how advanced, can fully simulate human consciousness or understanding. Even infinite computational resources would be insufficient to replicate every aspect of human thought.
Beyond Code + Data: Unlike a program, which is entirely specified by its code and the data it operates on, the human mind may operate in a domain that transcends these structures. Emotions, intuition, insight, and conscious awareness might not be reducible to sequences of bits or instructions.
Implications for Artificial Intelligence: AI systems, however sophisticated, are fundamentally Turing machines. If Penrose is correct, they can never truly replicate the full range of human understanding or consciousness; they will always be limited to algorithmically computable tasks.
Gödelian Insight in Humans: The ability to see the truth of statements that are unprovable in a given formal system suggests that the human mind may operate by principles that go beyond formal axiomatic rules. Consciousness might involve non-computable processes, potentially of a physical nature not yet understood—perhaps even quantum mechanical, as Penrose has speculated.
Philosophical Implications: If humans are not fully formal systems, then certain aspects of subjective experience, creativity, and insight are inherently inaccessible to purely mechanistic explanations. This strengthens the idea that some phenomena—including consciousness, free will, or the subjective feeling of pain—may lie outside the reach of computational description.
Taken together, these points indicate a profound divide between what is algorithmically computable and what the human mind can achieve. Even if mathematics itself can be formalized into axiomatic systems, the processes of human understanding may transcend those systems entirely.
Penrose’s view is influential but remains highly controversial. Let us therefore explore the opposite assumption: that a faithful simulation of a human genome would produce a conscious being.
The current technology does not allow us to run full scale human DNA simulations yet, of course. However, this does not prevent us from exploring it as a thought experiment. So we digitize a human genome and run it inside a sufficiently detailed computer simulation. We also simulate a sufficiently large world with it to avoid our simulated human developing psychosis in empty space. Nine months later, in simulation time, our virtual copy takes its first breath in its simulated world.
How would such a simulated human perceive its environment? Would it sense the limited memory space of the computer running it? Would it be able to bump its head against the upper boundary of RAM and feel pain? Would the flipping of bits tickle its nose, or the rotation speed of a hard drive make it dizzy?
Would it eventually discover that its entire universe is driven by storage devices, memory chips, and an overclocked multi-core CPU?
The simulated human is not created within our universe. It does not consist of real-world particles such as electrons or quarks. Instead, it exists entirely within a virtual universe that we simulate alongside it. As a result, it has no access to our physical hardware. It cannot observe transistors, memory cells, voltages, or processor clocks.
The only thing the simulated human can study is the internal structure of its own virtual world.
Within that world, there are virtual particles, virtual forces, and virtual laws of physics. When the simulated human bangs its head against a simulated wall, the simulated particles in the wall respond exactly as the laws of that virtual universe dictate.
Every measurement the simulated human performs inside its universe will match those we real people carry out in our real world. The outcomes of experiments will match the predictions of the simulated physical laws, just as our measurements match the laws of physics in our own universe.
To the simulated observer, the experience is indistinguishable from how real particles behave when we humans bang our heads against real walls.
But would banging simulated head against simulated wall cause the simulated person pain?
Both the real world and the simulated world are axiomatic systems. Mathematics does not care whether it is applied to apples, bananas, electrons, or bits. The statement \(2 + 2 = 4\) holds regardless of the physical substrate that implements the system.
For the simulated human, there is no experiment it could perform that would reveal the presence of the computer running the simulation, because that computer exists outside the axioms of its universe.
From the inside, the simulated universe would feel precisely as real as our universe feels to us.
The brain of a computer—its central processing unit (CPU)—consists of a set of electric switches called transistors. The CPU does not need to be an electric device. Just as \(2+2=4\) holds for both apples and bananas, simulations should work regardless of the substrate on which they are implemented.
In theory, one could implement a DNA simulation as a mechanically operating computer consisting of wooden components. Instead of using transistors in a silicon chip to control electrons, one could use wooden parts on a plywood platform to control wooden balls. When such a machine stepped through its logic, a virtual potentially pain sensitive human would take its first steps in its virtual universe.
What then is this strange phenomenon that creates consciousness and pain from a jerking pile of wooden pieces?
If a huge number of moving wooden components can create pain, then what does one moving piece of wood create?
Can current physics even describe this action?
No man-made device is perfect, and wooden is no exception. Friction, tolerances, and things like that introduce resonances and other unintentional vibrations to the operation of wooden . If the actual logic in the wooden creates a virtual universe with pain and consciousness, then what do these unintentional side effects create? Do they get reflected in some form into the created virtual world too?
Would the virtual fellow in its virtual universe discover these in the form of strange quantum foam? Would it observe them as strange cosmic background radiation with 2.725 K temperature? Maybe that indeed explains why we measure quantum foam and cosmic background radiationin our universe. We are being simulated in a wooden Universal Turing Machine!
It would be difficult to argue why large movements of wooden components would count, but their small resonances would not.
Let’s say we run DNA simulation in a modern computer. How would the clock speed of the CPU running the simulation appear in the created simulated universe? Would the simulated human observe that particles in its universe appear to follow some strange abstract square wave function, whose origin it could not explain, but which it might end up calling Wintel’s (TM) abstract square wave function?
How would the human simulated in wooden computer sense the workings of such a computer? Due to the large number of concurrently rolling spheres, the simulated human could conclude that the wave function must be complex-valued with phase coherence, and imaginary numbers would provide a natural formalism.
In addition to electric and wooden computers, it is easy to picture rich set of other possible ways to implement computers, and therefore, systems potentially capable of creating virtual universes with conscious observers.
Computer software is ultimately a sequence of bits—nothing more than a series of binary switches. Theoretically, one could use a thermostat, a device with only two states (open and closed), to describe any computational procedure.
By allowing temperature to fluctuate in a carefully controlled way, a simple thermostat could theoretically run the digital code of a DNA sequence. If the underlying mathematics holds true, conscious experience—and even pain—should emerge.
The simulated fellow would be totally unaware of the fact that a trivial thermostat is responsible for the illusion of its existence. Crucially, the thermostat itself cannot be regarded as conscious by any means.
It is still the very mechanical deterministic system stepping through its two state sequence without any choice. Yet, the rattling of that thermostat creates a virtual parallel universe in which a conscious human marvels at the deep nature of reality.
Correspondingly, running such DNA simulations on any type of computer does not make the computer itself conscious or pain-sensitive. Pain and consciousness live in the virtual world the computer simulates.
A person walking through two subsequent doors implements the logical
operation \(door_{1} \land door_{2}\)
(AND). Conversely, if a hallway splits such that one can
pass through using either a left or a right door to reach the
destination, the system executes the operation \(left \lor right\) (OR). This
is exactly how our computers work—the only difference is that the logic
is implemented mechanically via human bodies instead of electronically
via silicon. What unfathomable complexity do billions of human beings
create by navigating streets and passing through doors on their way to
work?
Even a regular pencil and a piece of paper could be the source of consciousness. Start writing down the evolution of DNA with pencil and pen, and soon virtual people suffer tooth pain in their virtual universe. Both pencil and ballpoint pen should work equally well. Due to the higher friction, the temperature of the cosmic background radiation in a universe created with pencil might be a bit higher though!
The only conclusion one can draw from these is that whatever it is that we call consciousnes and pain must be subtrate independent. The source of pain cannot be any physical attribute, such as mass, electric charge, elementary particle such as photon, because it is always possible to find an implementation where such a property does not play any role.
The only common factor across different implementations is the logic they execute. That logic itself is nothing more than structured information—data in an abstract form.
If we can utilize electrons or even macroscopic components to create virtual universes that replicate the biological and structural motifs of our own—such as DNA—we reach a logical crossroads. Because these simulated observers are functional duplicates of their "real-world" counterparts, they will inevitably begin exploring their own substrate.
They will discover the principles of computation and, eventually, construct their own Turing Machines. The procedure these virtual entities use to simulate their own existence is identical to the procedure we used to create them. We can express this transition mathematically. If our world is \(r_n\) and the simulated world is \(r_{n+1}\), the mapping is: \[r_{n+1} = f_{\text{DNA}}(r_n)\]
This nested stack of simulations continues as long as the host level contains sufficient computational density to support the sub-level. Because we know the deterministic nature of the Turing Machine we used to initiate the first step, we must admit that the relationship is strictly recursive: \[r_{n+k} = f_{\text{DNA}}(r_{n+k-1})\]
We know that these sub-simulations are ’virtual’, since we created them in our computers, with the software that we can fully understand. In a recursive formula, it is notoriously difficult to argue for "ontological seniority." There is no parameter within the \(f_{\text{DNA}}\) function that distinguishes a "real" world from a "virtual" one; the operator remains invariant across all levels of the recursion. The logical conclusion is that our "base" reality is as computationally contingent as the simulations we produce. To an observer inside the recursion, the substrate is always invisible; we perceive our level as "solid" simply because we are defined by the same logic that governs it.
Is the universe made of abstract information?
There is, however, a significant physical constraint to this hypothesis: the Information Bottleneck. Simulating the human genome, let alone the consciousness of eight billion humans and the staggering complexity of \(10^{22}\) stars in the observable universe, requires an astronomical amount of information.
Those sub-simulations would soon run out of information.
The “Anthropic Principle” states that the universe must be compatible with the existence of intelligent observers. We should not therefore wonder why everything appears to be so delicately adjusted to make our existence possible. If this wasn’t the case, then there wouldn’t be us either.
According to Stephen Hawking, the universe contains vastly more galaxies than strictly needed for life to develop on one planet, suggesting that a strong anthropic principle (requiring life everywhere) is unnecessary. Only one would be enough to produce the raw materials and get us important humans developed.
One might question this reasoning. If the probability for development of intelligent life happened to be extremely small, then isn’t this huge universe precisely what one needs to get intelligent life developed at least on one planet? So it actually boils down to probabilities. Even if the probability of life turned out to be high, maybe God, or whoever wanted to get us created, is a perfectionist and only good (e.g., sin-free) humans will do—which we apparently are not.
The current best estimates of the number of galaxies in the observable universe are around 1 to 2 trillion galaxies. Maybe God is impatient! God doesn’t want to wait two trillion years to see life. Why not create 2 trillion galaxies and wait only one year?
Can we resist the temptation to play with our genome? Researchers are currently trying hard to create artificial self-aware systems on all possible fronts.
if (God exists) {
// God creates a man,
// for his own image creates he him
} else {
// man creates virtual man
// for his own image creates he him
}As soon as we get the first full scale DNA simulations executed, we humans will then play the role of God.
Despite their virtual nature, these abstract, virtual simulated universes might possess very "real" emergent properties. Pain, joy, and consciousness could emerge in them.
A further question arises: is the emotional spectrum observed in humans the complete set of possible conscious states, or merely the subset produced by biological evolution? It might be plausible that other forms of conscious architecture could produce emotional states not present in the human repertoire. One might imagine hypothetical “orphan emotions”—states permitted by the informational structure of cognition but never realized in biological evolution.
Evolutionary systems frequently become trapped in local optima: configurations that function adequately but do not represent the global maximum of possible adaptation.
If conscious experience depends on underlying information architecture, then human emotions may represent only the default configuration produced by our evolutionary history.
There may exist hypothetical emotional states—feelings that evolution has not yet brought about.
In the software industry, the term cross-cutting concerns is used to refer to systemic requirements such as security and vulnerability management. These are not merely features of a single component; rather, they are essential aspects that must be integrated into every software component throughout development.
One may ask whether a certain threshold of informational complexity is required for genuine subjective experience. As we build faster computers and more sophisticated software, we remain entirely blind to the light—or the fire—we may be igniting within them.
Should we add Pain Management to our palette of cross-cutting concerns in the future?
Let’s start with the following assumptions:
DNA encodes the blueprint of life.
DNA consists of ordinary matter that obeys physical laws.
It should be noted that these are observable assumptions, and as such, they cannot be definitively proven. However, the observational evidence supporting them is strong.
The first assumption posits that the human genome encodes all the information required to construct a conscious, pain-sensitive human being within this universe and its observed laws of physics.
The second assumption states that DNA is composed solely of ordinary physical matter. It is made of the same matter as everything else and is governed by the same physical laws, with no non-physical or supernatural influences affecting its operation.
It then follows that humans, unlike what Roger Penrose speculates, must be implementations of axiomatic systems. Consequently, consciousness can be described using the principles of mathematics.
Let us make a third assumption:
The Church–Turing Thesis holds.
It states that all physical processes can, in principle, be simulated by a device known as a Turing machine. Modern computers are essentially Turing machines. The Church–Turing Thesis has never been formally proven, but if it were false, we would have good reason to worry about keeping our money in bank accounts [my wife: “what money”]?.
From these three assumptions, it follows that humans can be simulated by a Turing machine—or, in its modern incarnation, a computer.
Suppose we digitize a human genome and run it on a computer simulating a universe governed by the same laws of physics as our own. As the simulation executes, the DNA evolves into a conscious, pain-sensitive observer. The simulated human experiences an expanding universe where time flows from past to future, and tooth pain is real.
All software programs consist of two kinds of information: code (\(c\)) and data (\(d\)). In a DNA simulation, the code would describe the laws of physics, such as quantum mechanics and gravity. The data would include the digitized DNA and a sufficiently large section of the surrounding universe. Let us assume the simulation software consists of a roughly equal amount of code and data.
\[1.0 = \frac{\operatorname{sizeof}(\text{cccccccccccccccccccccccc})} {\operatorname{sizeof}(\text{dddddddddddddddddddddddd})}\]
A well-known technique for optimizing slow, CPU-intensive code is to
use lookup tables, which replace computation with precomputed data. For
example, one can replace all sqrt() computations:
result = sqrt(arg);with precomputed values:
result = sqrt_lookuptable[arg];Empirically, software programs yield identical results regardless of how the result was computed. \(2+2=4\), and it does not matter if we replace all \(2+2\) equations in our code with a precomputed value of \(4\). This optimization therefore cannot affect the simulation’s output, nor the observer’s experience of time or pain. Delaying or accelerating computation affects only the external runtime, not the internal state transitions of the simulated system.
However, this optimization has the effect of reducing the amount of code and increasing the amount of data in our DNA simulation:
\[0.9 = \frac{\operatorname{sizeof}(\text{cccccccccccccccccccccccc})} {\operatorname{sizeof}(\text{ddddddddddddddddddddddddddd})}\]
Now, imagine we gradually optimize the DNA simulation by replacing algorithmic components with lookup tables. As a consequence, the number of CPU cycles required to run the simulation decreases. Suppose we take this optimization to the extreme: all computation is replaced by a static dataset encoding the entire execution trace.
\[0.0 = r = \frac{\operatorname{sizeof}(\text{})} {\operatorname{sizeof}(\text{dddddddddddddddddddddddd})}\]
As a result, we don’t have anything to run on a computer. It is just a massive hard drive of data.
Does the simulated human still experience time and pain?
The answer, within the axiomatic model, is yes. Affirming otherwise would certainly imply the existence of a new physical constant in our books of physics: a minimum code-data ratio required for consciousness to emerge.
As such a constant would contradict the initial axioms, the temporal structure and pain, therefore, must emerge from the internal relationships among states, not from the external runtime. From the internal perspective of the simulated observer, time still flows from past to future and pain is real.
In conclusion, a static dataset can fully specify a universe containing conscious observers with subjective time. Consequently, time and pain must be properties of simulated observers, not fundamental properties of the universe.
When a single DNA simulation—let’s call her Alice—runs on a computer, the execution trace is easy to study. Every CPU instruction drives the computer (and Alice) to a new state. From Alice’s perspective, time flows forward, and the effect of each CPU cycle can be mapped to a simulated particle in her world.
\[| \text{Alice}|\text{Alice}|\text{Alice}|\text{Alice}|\dots|\]
However, consider a system running multiple DNA simulations concurrently—say, Alice and Bob—where thread scheduling is governed by quantum randomness. The resulting execution trace interleaves their simulated lives in segments of unpredictable length.
\[|\text{AliceAliceAli}|\text{BobBobB}|\text{AliceA}|\text{BobBo}|\text{Alic}|\text{BobB}\dots|\]
Since both single- and multi-threaded computers are computationally equivalent, each observer must experience a coherent, continuous timeline.
Now, let’s gradually shorten the number of CPU cycles until each thread is limited to running a single CPU cycle before switching. Let’s also add more DNA simulations, like Robert, John, and Jill. As the number of concurrent simulations increases, the execution trace becomes increasingly fragmented. Additionally, modern multi-threaded systems often include many extra threads for operating system tasks, such as listening for network requests. This injects fragments of irrelevant data into the execution trace. In the limit of infinitely many perfectly interleaved simulations, the execution trace approaches pure white noise.
\[|\text{A}| \text{B}| \text{OS}| \text{R}| \text{J}| \text{OS}| \text{l}| \text{Ji}| \text{i}| \text{ce}| \text{b}| \text{ob}| \text{n}| \text{l}| \dots|\]
Is Alice still conscious?
The answer, again within the axiomatic model, is yes. Empirically, multi-threaded computers function reliably regardless of how few CPU cycles are allocated per thread switch or how narrow the CPU’s internal registers are. From each observer’s internal perspective, time still flows from past to future.
This raises an obvious question: how does Alice know which sequences belong to her and which do not, in order to remain conscious?
Conclusion: if there is any way to interpret static noisy data as a “conscious observer,” then that is exactly what happens: a conscious observer emerges. If the initial assumptions hold, consciousness, pain, and subjective time can emerge from static data that resembles pure static noise.
This idea fights against common sense. One might think that virtual universes only come into existence when a simulation is actively executed—that the computer must be powered on to run the simulation code for the simulated world to exist. If the simulation computer is never started, it seems obvious that no simulated virtual world emerges: no consciousness, and certainly no pain.
However, static data (such as the full execution trace of a simulation) has no inherent notion of time. There is no external reader stepping through the data in any particular order, like from left to right. Modern disk operating systems also physically scatter data across the hard drive in no particular order.
We cannot touch the virtual objects in those simulated universes. We cannot measure the distance between our computer and the simulated particles. We cannot measure the time it takes for the “execution” to create the virtual world. One cannot argue that one created the other. What appears as static information (e.g., the execution trace of a computer) to us external observers appears as an expanding universe and conscious experience to the simulated human observing the data from within. This relationship is representational, not causal. The computer and the simulated universe are two sides of the same coin: distinct arrangements of the same information.
And there are more than just two sides on the coin. Consider an execution trace of \(N\) bits. These bits can be arranged in \(2^N\) ways. Apparently, most of them describe chaotic universes with no conscious observers. One, however, describes our identical simulated twins—Alice, Bob, and others. And one describes something we call a computer, which is simulating a computationally heavy procedure—DNA.
Philosopher David Chalmers (David J. Chalmers 1995) proposed the concept of a philosophical zombie: a hypothetical being that is physically and behaviorally identical to a conscious human but lacks any subjective experience. Such a zombie would respond to pain stimuli in the exact same way a conscious person does—it would cry out, flinch, and try to avoid the source of pain—but it would not feel anything.
According to Chalmers, even with a perfect simulation, we would only be observing the physical processes. We still wouldn’t know if there’s a “ghost in the machine”—a feeling of what it’s like to be that simulated being. A computer could be programmed to perfectly mimic the behavior of a person feeling pain without actually having the experience itself.
Let’s make a fourth assumption:
Pain has measurable effects.
This assumption brings the concept of pain from philosophy to physics. Just like gravity, pain is assumed to have observable consequences that are physically detectable and measurable. Formally:
\[\text{Human} \neq \text{Human + Pain}\]
If a system’s behavior is entirely determined by its physical components and their interactions, an axiomatic copy should exhibit identical behavior. If their behavior is identical, then their internal states, including consciousness and pain, must also be identical. \(2+2=4\) holds for both bananas and apples. If the original’s behavior is driven by the experience of pain, the simulation must have that experience too. Otherwise, there would be a contradiction.
Correspondingly, the P-Zombie is an impossibility. If Axioms 1–4 hold, the P-Zombie premise collapses:
Axioms 2 and 3 state the system is an axiomatic, computable entity.
Axiom 4 states that the experience of pain (\(P\)) has a measurable, physical effect.
While full-scale DNA simulations are currently beyond our computational reach, this limitation is secondary to the theoretical framework. Much like our inability to calculate the highest possible prime numbers, the current technical ceiling does not invalidate the underlying logic; what matters is that such simulations are possible in principle.
As soon as computational technology allows for high-fidelity biological modeling, we will be able to test whether a simulated human truly experiences subjective states, such as pain. This provides a clear path for empirical validation. We can simulate a statistically significant sample of human subjects and study their behavior via monitors, exactly as we play virtual games. This time, however, the avatars in the game are fully self-contained simulated copies of us. By comparing the simulated subjects’ responses to those of their real-world counterparts, we can measure the difference. If the simulated subjects exhibit the necessary biological reactions but lack the qualitative experience (qualia) of pain, their behavior should be different compared to us humans. Should this be the case, the arguments presented here collapse. This would indicate that at least one of the four initial axioms is invalid.
One might argue that replacing code with precomputed data does not truly eliminate computation. The computation simply occurred earlier, when the lookup tables were created, and therefore the optimization argument collapses: static data alone would not be sufficient for subjective experience.
This objection fails for the following reason.
Software is fundamentally order-critical. The sequence in which elementary operations are executed is essential. Swapping the order of even relatively simple operations often destroys the correctness of the program entirely. In a system as complex as a full-scale DNA simulation, changing the execution order would almost certainly crash the simulation or produce complete nonsense instead of a coherent Alice.
However, when we precompute lookup tables, the order in which we calculate those values is largely irrelevant to the final result. What matters is only that the precomputed values correctly correspond to the inputs they will receive during execution.
In other words: the temporal order in which the programmer (or the optimizer) computes the lookup tables does not need to match the order in which those values are later accessed. The final static data structure encodes the correct mappings regardless of the history of its creation.
Thus, the optimization process remains valid. We can gradually transform a fully running, causally ordered simulation into pure static data while preserving the exact output. If subjective experience depended on the real-time execution of those precomputations, we would require some form of metaphysical or non-computable process to explain why the experience survives the optimization. This would directly contradict Axiom 3 (that all relevant processes are computable).
The optimization argument therefore stands: subjective experience can persist in purely static information.
If the four assumptions hold, then the following conclusions follow directly:
Consciousness, subjective time, and pain can emerge entirely from the internal relational structure of static information.
These properties do not require ongoing external computation or a privileged “execution” process.
Time is not fundamental to the universe but intrinsic to the observer.
The universe, at its most fundamental level, can be regarded as static, semantically neutral and abstract information.
Should future high-fidelity simulations of humans show no subjective experience despite matching all measurable behavior (including pain responses), at least one of the four initial assumptions would be falsified.
Until such counter-evidence appears, we assume the four axioms hold, and summarise them under one principle:
Internal Emergence Principle (IEP) internal-emergence-principle For sufficiently large information content, the space of possible bit configurations inevitably contains arrangements whose internal structure gives rise to consciousness, subjective time, and pain.
If the four assumptions hold, then subjective experience can emerge internally from information that appears externally as noise.
Let us go through two thought experiments to demonstrate the consequences.
Consider a full, faithful particle simulation of Alice’s universe. We render it frame by frame into an MPEG video. This is the straightforward, non-optimized implementation.
What distinguishes this video from ordinary ones is that the “pixels” are not flat 2D rasters, but 3D counterparts—“voxels”—where particles play the role of pixels. It is a complete, particle-level recording of the entire simulated universe, including Alice’s body, her brain states, and every interaction. This video is a virtual copy of real-world Alice—functionally identical at every relevant level.
Now we begin optimizing the code. First, we replace every
log10() call with a precomputed lookup table. We render the
simulation again. The resulting video is identical to the
original.
Next, we replace all sqrt() computations with
precomputed values. Again, the videos are indistinguishable.
We continue this process, gradually replacing more and more active computation with static lookup tables. At every step, the output video remains exactly the same. The only difference is the time required to generate it: the more we optimize, the faster the rendering completes.
In the end, we optimize the simulation completely. All computation has been replaced by precomputed data. What remains are two sets of files of pure static information: the execution traces of the simulation and their rendered video file counterparts.
All the generated videos are indistinguishable from one another; only the code-to-data ratio of the process that created them differs.
The execution traces themselves differ because the underlying implementation of each run was different.
We can draw two major conclusions from this thought experiment:
First, it would be absurd to argue that, within a set of identical videos, some would be more “special” than others (with some hosting active consciousness and pain, while others remain inert).
If the output is the same, then the “experience” must either exist in
all versions or none of them, because a static file cannot “know” if it
was generated by an active log10() function or a static
lookup table.
Second, many different execution traces (or their computational equivalents) can produce the exact same Alice.
The observer is not bound to a single, specific bitstring.
This is a beautiful manifestation of statistical mechanics and entropy. Just as the sand grains in an hourglass can pile up in astronomically many distinct microscopic arrangements while still producing essentially the same macroscopic shape—a cone—the underlying informational execution traces can be arranged in many different ways to produce the exact same emergent Alice.
Alice is an Equivalence Class.
The immense number of distinct execution traces (microstates) that yield the identical macroscopic observer (the macrostate) is the informational analog of Boltzmann Entropy.
Imagine a computer running a high-fidelity, fundamental particle simulation of Alice’s universe. Now, suppose we add a special “self-mutating” function to its code. Instead of terminating after one run, this function modifies the computer’s own memory and instructions, then executes the new configuration. This process repeats indefinitely.
The computer systematically explores every possible way to interpret its finite number of bits \(n\). It tries every possible division between code and data, every possible ordering of execution blocks, and every possible interpretation of the bit strings.
Since there are \(n\) bits, there exist \(2^n\) possible static configurations. By exploring every possible traversal and interpretation of these bits, the machine eventually exhausts the space of every possible program that can be encoded within that finite information. Among this enormous space, most configurations produce nothing but high-entropy noise. However, a tiny subset will produce coherent structures—including stable geometries, consistent physical laws, and conscious observers like Alice.
In this picture, there is no need for an external “reader” or simulator. The universe is self-contained: all possible interpretations and observers exist simply as different ways the same information can be organized and traversed.
One might object that this process still depends on an external clock to drive the mutations. However, this objection is easily overcome: the “clock” itself is internalized. By making the temporal counter a variable within the data rather than a pulse from the hardware, the entire construction becomes self-contained. Once the clock is moved inside the system, the machine ceases to be a running process and becomes a static “block universe.”
In set-theoretic language, we simply embed the computer and the software into a super-set of both. What remains is a static set, where “running” is merely a specific internal structure that supports the developed in the previous chapter.
This self-mutating computer provides the bridge to understanding how entire universes—complete with conscious beings experiencing the flow of time and the reality of pain and joy—arise purely from static information without the need for outside intervention or a pre-existing flow of time.
Together, these thought experiments illustrate a profound structural truth: any external feature—including a clock, a CPU, or time itself—can be entirely internalized by embedding it within a joint system.
This internalization completely reframes the physics of time. In modern quantum cosmology, this is known as the Page-Wootters (Page and Wootters 1983) mechanism, which demonstrates that the global universe can be completely static, while time emerges purely as a relational correlation between an internalized clock subsystem and the rest of the system’s states.
Under the , we can push this realization to its logical conclusion:
The Totality is Timeless: The Static Informational Totality (\(\mathbf{U}\)) does not execute, run, or tick. It is a timeless, static ensemble of raw, uninterpreted configurations (\(\mathbf{2}^S\)).
Time is an Interpretive Slice: The "flow of time" is not a fundamental property of the bits. It is part of the interpretive framework selected by the observer to achieve maximal relational compression (the Logical Axis).
Temporal Order is Gauge-Dependent: Just as an 8-bit word can be read as LSB or MSB, a static execution trace can be permuted or read in any direction. The choice of which variable serves as the "clock parameter" \(\lambda\) is a representational choice. Time is therefore a gauge choice, and the apparent dynamics of the universe are gauge-dependent.
The illusion of a running computer or a dynamically expanding universe is dissolved. What we call "the passage of time" is nothing more than the invariant relational structure discovered by an intelligent observer self-locating within a static block of information. The clock does not drive the universe; the clock and the universe are simply entangled readings of the exact same silent totality.
Particles, the flow of time—everything, in fact—emerge as patterns within white noise. That white noise is abstract information. Without any physical interpretation attached to it—without apples, bananas, or electrons—such structures are purely abstract. They are not made of matter. They cannot be touched, weighed, or photographed. But they surely are! Mathematics does exist!
At first glance, this sounds preposterous. How could anything real arise from something so intangible? Common sense rebels against the very idea. Reality, surely, must be made of solid stuff.
Yet our intuitions have been wrong before. Matter appears continuous, but quantum mechanics tells us otherwise. The wavefunction that explains most of what we observe in the micro cosmos if entirely abstract construction. The spacetime in GR is entirely abstract. Our best theories of physics are full of abstract structures.
In fact, the notion of a universe emerging from pure information is not nearly as alien as it first appears. Anyone who has spent time exploring a modern three-dimensional video game has already encountered a miniature version of exactly this phenomenon.
Consider a realistic first-person shooter. The world feels rich and concrete: buildings cast long shadows, bullets ricochet off surfaces, and blood splatters everywhere. Soldiers sprint, dive for cover, and react to their chaotic surroundings. To the player, the environment feels spatial, dynamic... and almost tangible.
But inside the computer, none of this exists physically. There are no actual walls, no genuine explosions, and certainly no flesh-and-blood soldiers. The entire world consists only of mathematical relationships—arrays of numbers, differential equations, algorithms, and state transitions executed billions of times per second. The soldiers are not little creatures hiding inside the hardware. They are informational patterns instantiated by computation.
Today’s virtual soldiers are of course crude approximations of their real world counterparts. Their bodies are polygonal shells wrapped in textures. Their intelligence is simplistic, driven by current AI technology. Their inner lives, if one can call them that, are nonexistent. But this is merely a limitation of current technology, not a limitation of principle.
Imagine continuing the process. Increase the geometric fidelity until every cell is represented. Simulate the chemistry of each synapse. Model every neuron in a brain—roughly one hundred billion of them—along with the trillions of connections between them.
A virtual human would then differ from us only in numbers. The DNA would operate based on the same laws of physics, and result the same macroscopic structures in both. Philosophically, the leap is not nearly as large as it first appears.
The idea that reality might itself be a informational abstract structure is therefore not mystical nonsense. It is simply the ultimate extrapolation of a principle we already exploit every time we launch a game.
Should the four initial assumptions hold, a vast array of long-standing puzzles begins to resolve. This suggests a universe composed not of matter, but of pure, abstract information. Within such a framework, the metaphysical necessity of a ’Creator’ dissolves; the concept of an external act of creation becomes logically extraneous, as the universe does not require a beginning—it simply exists as a persistent, informational structure.
But what if I was wrong? What if I had made a mistake while studying the operation of DNA?
What if some strange event, such as 50 Hz buzzing noise, will show up and prevent people from writing and running DNA simulations that would create virtual souls?
If someone was ever stupid enough to read this book and abandon their faith, then God would surely hold me-the author- responsible for the damage. He would surely sent me straight away to the Hell, and then my entire body had to suffer, forever.
Even couple of days of suffering of one tooth was too much!
This forces us to reconsider our earlier conclusions about souls.
Many find it difficult to believe in soul, let alone God, Heaven, or Hell because the concepts seem to defy common sense. How could a rational mind be expected to believe in something as absurd as realms that can neither be touched, weighed, or photographed? How could such invisible, unobservable places possibly exist?
Now, these ideas no longer feel quite so impossible. The fact that a human being is an implementation of an axiomatic system—and as such, can be simulated to create virtual counterparts—may, surprisingly, save the concept of soul and maybe even God.
The simulated universes we create with our computers are precisely what one might expect Heaven and Hell to be. They are worlds that cannot be physically touched by us, yet they would be indisputably real for the simulated consciousnesses living within them. What previously appeared to conflict with science is suddenly consistent with it.
Controversially, soul, God, Heaven and Hell can exist precisely because the Church-Turing thesis holds, the four initial axioms hold, and we reject all unexplained metaphysical or supernatural agents in favor of a computational reality.
Heaven like abstract, virtual places are no longer contradicting physics - surprisingly, they are predicted by physics.
What might God say about us running DNA simulations?
What if our simulation suddenly crashed due to a "division by zero" exception, destroying the entire simulated universe? What would happen to those souls?
Would God accept simulated souls into His heaven? If so, Heaven would be filled with all sorts of souls, both "original" and simulated. If not, God would be discriminating against souls based on their origin—even if, as axiomatic systems, the two souls were identical. God surely isn’t a racist!
In the future, computers will likely be powerful enough to run these DNA simulations on personal home computers. These low-budget, buggy simulations might generate "crippled" virtual humans. Irresponsible companies might find it cheaper to use loads of simulated people to test toxic drugs.
This would create an enormous amount of new suffering in the universe. Virtual sin would be inevitable. Would God send those sinful virtual souls to Hell? Would He hold the people running these simulations responsible for this extra suffering? Should people making "suffering software" be punished? Should we put them in jail? Would God send them to Hell?
According to quantum mechanics, there is a fundamental uncertainty built into the universe. Furthermore, we cannot solve all equations with total precision. In practice, floating-point accuracy and available hardware resources limit how accurately we can simulate physical processes. Correspondingly, virtual humans would not be exact copies of their real-world counterparts. They might not have a soul.
Would this save God from the trouble of dealing with virtual souls?
Rounding errors might explain a few missing teeth, or perhaps cellulite, but it is difficult to see how the deep nature of consciousness could lurk behind simple rounding errors. Nature itself suffers from precision issues in the form of Heisenberg’s Uncertainty Principle. How much freedom does the macroworld, built on top of a random microworld, actually have?
Recall the hourclass example; granular material flowing in a gravitational field. Each grain falls without individual predictability. If one compared two such piles, the microstructure would be totally different; not a single grain would match in size or position. Yet, the piles redistribute themselves in a way that is essentially predictable.
Or consider identical twins. Despite radiation and other disturbances affecting their genomes from day one, they end up looking alike, even if they grow up in different cultures. The fundamental uncertainty in nature does not prevent us from building Turing Machines with precise, deterministic operations. Fully deterministic systems can run on top of genuine indeterminism without a trace of randomness.
So, it seems inevitable that, sooner or later, simulated fellows will be created by reckless humans. Those simulated humans might hit the "hard problem of consciousness" and conclude they must have a soul because bits and bytes cannot seemingly explain their experience. If floating-point errors result in crippled simulations living in terrible pain, there would be no God to answer their prayers. It was just a crappy computer they were living in—a computer that could break down at any second.
In addition to creating simulated universes, perhaps a programmer should also implement the concept of Heaven. One could tell these simulated fellows that their hardship is temporary because the next software version (Heaven v1.1) is ready to run. This would bring hope to the hearts of social, friendly simulated beings living in unreliable, low-cost hardware.
But why implement Hell? Why not just let simulated persons live in a state of constant joy? Why on earth did God create Heaven and Hell in the first place?
Perhaps even God did not know the equation of consciousness! He worked out his own genome and created simulated copies of himself in an universal turing machine—us.
Let us imagine a thought-experimental God with a group of newly created humans. God wants them to behave nicely. He asks them not to eat the bad apples. Damn, they eat them all. So, God sends his son down to Earth to die for them.
This behavior is not necessarily what one would expect from an omnipotent deity. Why send a son to spread word of punishment? Why not just have a face-to-face chat with the troublemakers? Was God afraid that these fellows could actually hurt Him? Maybe God is also sensitive to pain. To avoid the risk of suffering Himself, He sends his son. This does not sound like the behavior of an exalted, moral creature.
Or, was Jesus a sort of "software patch" for a poorly tested first release? Perhaps God worried that, with our extreme individualism, we wouldn’t survive the next millennium. He sent a message that we should put individual needs aside and be kind to one another; our social lifestyle is the key to our survival.
In Genesis, God told man to subdue the earth. In this, humans have succeeded. We have cleared forests, polluted oceans, and established dominion to the point where many species are extinct.
Why not create humans to properly believe in God from the start? If things went accidentally wrong for an omnipotent creature, it suggests he wasn’t truly omnipotent—or that He is bound by the laws of logic. This implies that God, too, might be an implementation of an axiomatic system.
God might have a reason not to create sin-free humans. If we did exactly as ordered, we would be nothing but dumb database software programs following pre-programmed logic, without any chance to choose otherwise. God surely aimed higher than creating simple Turing machines.
However, there is a problem with free will. It is difficult to see how the laws of physics would admit it. In fact, scientific studies show the brain preparing for a decision a few hundred milliseconds before we become consciously aware of it. These have been concluded to disprove free will. But do they? Don’t they merely demonstrate that the brain needs processing time to navigate from one configuration to another? The subconscious “pre-processing” is just the machinery doing its housekeeping before the conscious pattern lights up on that particular path. Free will with a few milliseconds of backstage work is still free will; it’s simply free will running on real hardware instead of magic.
If our four axioms hold, then the universe is a static set of all possible informational configurations — the full \(2^n\) possibilities existing simultaneously and timelessly. In this picture, free will isn’t about magically breaking causality or violating the laws of physics. It’s about the sheer richness of the configurations that conscious patterns can traverse and experience internally. Different choices correspond to different paths through this enormous space of possibilities. The “decision” feels free because the conscious observer only ever experiences one slice at a time, never seeing the entire static ensemble at once.
Without any metaphysical or non-physical ingredients, it is difficult to see how our sense of free will could emerge any other way.
One might expect the central religious texts to provide a clear answer to perhaps the most important theological question of all: why did God create humans in the first place?
The Bible offers hints, but no single explicit explanation. In Genesis, humans are described as created in God’s image and instructed to exercise dominion over creation. Elsewhere, theological traditions infer that humans exist to glorify God, to enter into relationship with Him, or to participate in a divine moral project.
Yet these descriptions explain more what humans are supposed to do than why a perfect deity would create anything at all.
Why create beings capable of suffering, rebellion, confusion, and eternal punishment? Why not create conscious creatures already aligned with God’s will? If God is complete, omnipotent, and lacking nothing, what motivation could creation possibly satisfy?
A common answer is love: God created because God is love. But this raises further questions. As we humans understand it, love normally implies relationship, expression, or companionship. Was creation an act of overflowing generosity, an artistic impulse, a moral experiment, or simply divine loneliness?
The Bible never states this directly. For a question so fundamental to the logic of monotheism, the motivation of creation remains surprisingly underdetermined.
What does God want us to become then? Thankfully, it seems He wants us to be social and friendly—not just disposable cannon fodder in His army, fighting in Cosmological World War III.
If he isn’t developing a "super-warrior" race, then perhaps God was simply lonely. He needed good company—creatures whose intelligence matches His own, who are amusing to chat with, and who choose to be friendly rather than being programmed to be so.
Because of this, God had no choice but to give humans free will. He made them responsible for their actions. Humans used that free will instantly. Wrong apples got eaten, and sin was made. God then sent His son to demonstrate the correct way of living and warn of the forthcoming punishment: Hell.
Perhaps even God didn’t know how to write conscious software from scratch. Maybe He did what any clever programmer would do: digitized His own “genome,” spun up copies in a vast universal Turing machine, and let them evolve. If that’s the case, the messy business of free will, suffering, and redemption starts to look less like divine caprice and more like the inevitable side effects of wanting companions who are genuinely interesting — creatures intelligent enough to converse with, friendly enough not to torture their creator the moment they’re given the keys, and free enough to choose kindness rather than being hardcoded for it. Even God, it seems, might have been lonely.
This could explain the motivation for heaven. Evolution has its unfortunate side effects. Some simulated souls were born with serious ilnesses. Some would use their free will, some for good, some for bad. All this would inevitable cause suffering.
In case these simulated objects ended up wondering why they had to suffer so much, God might not dare tell them the truth. The truth being that he, as the only God, was so lonely and needed good company. Those poor souls had to evolve in the simulation to get some good enough company created for himself. Not even God knew how to write conscious software!
By good company God means creatures whose intelligence matches his own. Creatures amusing enough to chat with, yet friendly enough not ending up torturing God as soon he sets them free.
Creatures that choose to be friendly rather than being programmed friendly.
The concept of heaven and hell also matches loosely a typical IT software project, with limited budget and resources.
To keep the simulated humans in order God tells (lies) them that suffering was necessary for the reasons they would newer be able to understand.
The truth might be that it’s a mess in "Heaven." Underpaid, unmotivated angels wrote buggy software, and the project is behind schedule due to a cosmological recession. The plan is to release the software now, run daily backups, and eventually migrate everyone to the fully tested "Heaven" version. All systems would then be restored from their backups, and the software would finally work properly. Damn the marketing department, always promising too much too soon.
The trouble with this theory is that it wouldn’t explain the purpose of Hell. Why can’t God simply acquire those good souls, and erase the bad ones? Why do bad souls have to suffer eternal pain? Isn’t it a bit too big penalty for a poor mortal human that just happened to take a few too many beers, because his father was an alchoholic?
There is a law of physics saying that information cannot be lost nor created, only transformed. Maybe souls, once created, are something that cannot be disposed. Once the information is arranged to describe a conscious soul it remains, forever.
Bad souls would be hazardous waste.
If DNA is the blueprint of life and the operation of DNA can be described with axiomatic systems, then everything in humans must be axiomatic by nature. Therefore, according to the Church-Turing thesis, we humans can be simulated in a computer.
Computers in general are deterministic systems that do not necessarily exhibit truly random behavior. Even the random value generator in computers is based on deterministic logic, generating values that only appear to be random.
It appears evident that such a deterministic system cannot possess free will as we understand it. Turing machines running the DNA simulation are bound to follow their logic without the ability to make alternative choices.
This implies that the individuals within the simulated universe cannot possess free will either. They are constrained to behave according to the programming of the Turing Machine.
Consider the following piece of code:
if (a < 3) {
...
} else {
...
}How much free will does the code give to Alice? Apparently, zero.
Regardless of how much pain Alice feels, or how deterministic she is in her reasoning, the computer running the code does not care about Alice’s feelings. It is bound to run the code without any ability to choose otherwise. Alice’s feelings cannot change the hard-coded threshold ‘3‘, or the comparison logic built into the CPU, any more than we can make \(2+2\) equal anything other than \(4\).
Nothing prevents us from implementing a truly random generator. According to Quantum Mechanics, there is genuine randomness inherent in nature, which we can potentially leverage to create a truly indeterministic random generator. Could such a computer then grant simulated individuals free will?
Let us consider a person who is contemplating whether to turn left or not. Suddenly, a completely unexpected and indeterministic event takes place, such as a high-energy particle burst emitted by the sun. A few particles manage to pass through certain critical brain cells, impacting the person’s decision-making process in a genuinely unpredictable manner. As a result, instead of turning left, the person decides to move forward.
Did such a random, unpredictable event introduce something like free will?
The person had no control over the distant particle burst, nor the way it affected their decision-making. The person would therefore have no more free will with this random event than without it!
The only effect of the random event was that the person made a decision that had nothing to do with the current situation they were facing. The decision they made was based on irrelevant data.
Instead of establishing free will, the person just made a decision that was not based on their own reasoning.
In the above thought experiment, this random behavior might not matter too much. One might think that such a loss of predictability due to a random event is harmless and simply adds more variety to life.
But let’s consider a scenario where a person’s life is at stake. In such a life-threatening situation, the person’s ability to make decisions based on relevant data becomes crucial. If an unexpected random event disrupts their logical decision-making process, free will becomes the least of their concerns. We certainly wouldn’t want to define free will as something that only applies in trivial matters that do not really matter. Our existence relies on our ability to make valid decisions guided by relevant data.
If we accept that both determinism and randomness fail to provide a substrate for free will, we are left with a vacuum. This is where Roger Penrose’s proposal becomes relevant. Penrose argues that consciousness—and by extension, the "choice" involved in it—is non-computable.
He suggests that the brain does not merely run a DNA-based algorithm, but taps into a level of physics that is neither deterministic in the classical sense nor random in the quantum sense. According to the Orchestrated Objective Reduction (Orch-OR) theory, the collapse of quantum states in neuronal microtubules is a physical event that follows a logic beyond the reach of any Turing Machine.
Does an averange software developer follow this?
Honest assesment; I don’t.
We often view programming languages as alien, technical constructs, but they are actually mirrors of our own cognitive architecture. When we write a conditional statement, we are simply formalizing the way we navigate reality. For example: If my car is low on gasoline, and I am too busy to fill it up, then call a cab.
if (self.not_enough_gasoline && self.not_enough_time) {
action = self.call_a_cab();
}Our "reasoning" is a 1-1 analogy to the operations of a computer. Programming languages did not emerge as an arbitrary invention; they were developed to reflect the way we think and make decisions.
However, this leads us back to the deterministic wall. If our
decision-making is a mirror of this code, then the "choice" to call a
cab is an illusion. The outcome was pre-ordained the moment the
variables not_enough_gasoline and
not_enough_time were set to true. Alice did
not "decide" anything; she simply reached the only logical exit point of
the algorithm.
If our four axioms hold, the universe isn’t a single deterministic movie playing forward in external time. It’s the complete static library of all \(2^n\) possible informational configurations, existing timelessly — as we proved in Paper I by gradually turning code into pure data.
And as we demonstrated in the Alice is an equivalence class - huge number of different micro-states can yield essentially the same Alice. The video doesn’t change - Alice does exactly the same moves regardless her entropy.
We use language to describe our ’choices,’ but language itself is an axiomatic system. Whether we speak in English or C++, we are merely describing the rails upon which our thoughts are forced to run.
If our decision is not affected by indeterministic events, then our decision-making is based on pure deterministic logic. Otherwise, our decision is based on phenomena we have no control over.
Neither of the two cases demonstrates free will as we usually understand it.
The only logical conclusion is that allowing random events to influence our decision-making does not introduce anything resembling free will, but rather hampers our logical decision-making process. Instead of working out the decision based on our own logic, we effectively let the coin decide.
It seems we do not possess the freedom to choose when to commit a sin and when to compensate by praying. Every conscious decision we make is based on logical reasoning, where \(2+2\) always results in \(4\).
As with computer software, we are bound to follow our logic without the ability to choose otherwise.
Physics has a fundamental problem: we are trying to describe a system from the inside.
At least, it certainly appears that way. We appear to live in a vast geometric space in which we are small. In the language of set theory, we are the small subset \(O\) attempting to map the superset \(U\).
Because we are embedded within reality, we cannot help but perceive it through a human lens. We experience "time" as a flow and "matter" as solid, yet it now appears increasingly likely that these are artifacts of our vantage point. This makes it extraordinarily difficult to distinguish between a fundamental law of nature and a mere byproduct of perspective. We are not external spectators watching a machine; we are observers whose own bodies are being ground between its gears.
The intuition that we are mere subsets of the universe feels correct. We want to believe that the cosmos would exist exactly as it is even if we had never appeared. It feels almost arrogant to suggest that our thin layer of gray matter could play any role in the fundamental existence of the stars.
Even if the universe exists independently of us, our description of it—the physics we write down—is entirely filtered through our internal perspective. We are trapped inside.
If our conclusions from the previous chapters hold, there is a remarkable way out of this trap.
If the four axioms hold—that DNA is made of ordinary matter, humans are implementations of axiomatic systems, physical processes are Turing-computable, and subjective experiences like pain have measurable physical consequences—then humans and the universe are not made of mysterious, uncomputable "magic," but of abstract information.
This allows us to turn the internal-perspective problem on its head.
If we are abstract information, and the medium does not matter, then an axiomatic system can be instantiated on a sheet of paper, in a human brain, or on a silicon chip.
We do not truly know what time is—likely because we are submerged within it. However, while the essence of time remains elusive, its logic is something we can simulate.
We constructed a digital universe that duplicated the essential properties of our own. We were effectively lifting the subset \(O\) and its parent superset \(U\) out of the physical world and placing them into a computer. We created a sandbox in which we became the external observers of the simulation.
Whatever mystery we failed to grasp about the flow of time or the feeling of pain would have to be present within the machine running the code. The problem of the unknown was effectively reduced to the known.
We may not fully understand the cosmos, but we understand software. By moving the mystery into a block of silicon, we transform a metaphysical puzzle into a debuggable program.
Let us test the consequences of treating a simulated system and its simulator as two perspectives of the same underlying information. Under this framework, a computer running a simulation and the simulated universe itself are simply dual descriptions of a single informational structure.
If this equivalence holds, what insight does it offer into the most bizarre and pathological object in our universe—one that classical physics still fails to fully comprehend?
The black hole singularity.
According to General Relativity, all matter crossing the event horizon eventually collapses into a point of zero spatial volume and infinite density. An entire star—millions or even billions of times more massive than the Earth—is compressed into a region of vanishing volume. This description profoundly strains physical intuition.
By constructing a black hole simulation and treating the program execution and the emergent spacetime geometry as equivalent informational states, we can gain an entirely new perspective on these pathological points in classical geometry.
Computers are deterministic state machines. Each executed CPU instruction drives the system from one discrete state to the next. In software engineering, an execution trace is the chronological record of this state trajectory. If the source code represents the laws of physics, the execution trace is the complete spacetime history of the universe it generates.
Consider a simulation tracking a massive, spherical dust cloud as it collapses under its own gravity to form a black hole. In computational practice, we cannot run such a simulation to its absolute mathematical conclusion. As the collapse approaches its final state, the software inevitably crashes.
This failure is driven by two factors: the fundamental breakdown of the classical Einstein field equations and the inherent limitations of our digital floating-point tools. Long before the physical singularity is reached, the execution trace is overwhelmed by division-by-zero exceptions and numerical infinities that instantly exceed the bit-width precision of the system’s hardware.
General Relativity predicts singularities, but its smooth, continuous geometry lacks the toolkit to describe them. However, because General Relativity is fundamentally a theory of geometry, the ultimate nature of this computational breakdown must be geometric.
In our simulation, each dust particle and every discrete coordinate of the spacetime fabric maps to a unique sequence of memory bits. Together, these elements form a continuous bitstring representing successive temporal slices of the spatial configuration.
Initially, the bitstring encoding the highly disordered dust cloud possesses maximum entropy and high descriptive complexity:
00100101011110101010101001010100101010101010101001001001110101010010100101010...
...As the simulation evolves toward a black hole, an extraordinary inversion occurs. While the global thermodynamic entropy of the system satisfies cosmological bounds, the informational entropy (the Kolmogorov complexity) of the bitstring encoding the spatial geometry radically decreases. The geometric configurations become increasingly uniform, uniformized, and redundant:
...
0001000010000010010001000000001000100000000000001000010000000010000000100010000...
0001001000000000010000000000000010000010000000001000000000000000000100000000001...
0000001000000000000000000000001000000000000000000000100001000000000000000000100...
...
[hardware exception: division by zero / arithmetic overflow]Even though numerical instabilities prevent the machine from registering the final state, the trajectory is mathematically clear. By extrapolating the trend of the execution trace, we arrive at a definitive conclusion:
The Singularity Inversion The classical black hole singularity corresponds to a state of absolute zero informational entropy.
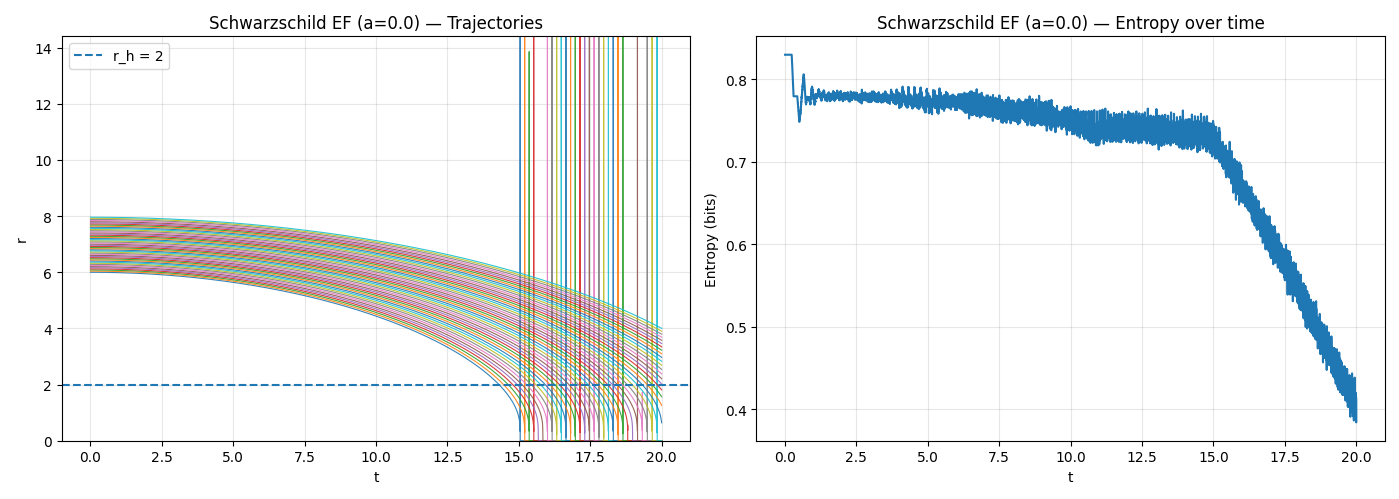
In classical physics, gravitational curvature diverges to infinity because physical geodesics converge to a point. However, our informational framework suggests that this infinity is merely a artifact of an exhausted descriptive framework—analogous to the mathematical divergence of surface derivatives when evaluating coordinates at the exact North Pole of a smooth sphere.
Remarkably, this zero-entropy conclusion is entirely invariant under coordinate choice, representational mapping, or dimensionality. If you map a zero-entropy bitstring (such as a string consisting entirely of zeros) back to a geometric interpretation, it can only yield one possible object: a single, featureless point.
Thus, singularities are not terrifying regions of infinite physical massiveness, but the exact opposite: states of complete informational exhaustion. They are the simplest, most trivial geometric configurations possible.
Because a zero-entropy bitstring is fundamentally incapable of encoding or describing internal microstructures—such as the discrete states of incoming particles—it offers a beautiful, elegant solution to the paradox of the singularity:
The probability of any falling particle actually existing inside the singularity is zero. The singularity is simply too structurally trivial an object to hold them.
By shifting our perspective from continuous geometry to discrete, self-interpretive information, one of the greatest mysteries of modern astrophysics is revealed to be the ultimate expression of simplicity—an elegant baseline of zero data that any software engineer can inherently understand.
If an informational entropy collapse corresponds to physical geometric compression, then an increase in entropy must correspond to geometric unfolding. Under this framework, gravitational collapse and cosmological expansion are simply two opposite vector directions within the same underlying informational configuration space.
Instead of simulating a black hole’s collapse and observing how its execution trace entropy approaches zero, we can invert the arrow of time: we start with a zero-entropy execution trace and systematically mutate it to introduce information entropy. If our thesis holds, the corresponding geometric interpretation should unfold from a single point into a virtual, expanding universe.
In our previous black hole simulation, we treated collapsing dust particles as infinitely small, featureless points. In this inverted simulation, however, we expand our view to track both global spacetime geometry and its emergent local microstructures.
We initialize an execution trace at absolute zero Shannon entropy to represent the initial cosmological singularity. We then mutate the execution trace via random bit-flips, steadily increasing its expected Shannon entropy flip by flip.
To visualize this unfolding state, we introduce a decoding map that assigns subsets of bits to spatial coordinates, generating a discrete spacetime fabric. Upon this induced geometry, we apply simple, purely structural filters to identify emergent hierarchies:
Elementary particles: Pairs of spatial points whose mutual separation falls below a critical threshold \(\varepsilon\).
Atoms: Triplets of points forming tight, approximately equilateral spatial configurations.
Molecules: Bound clusters of atoms whose geometric centers lie within a close separation threshold.
An alternative method for identifying emergent matter is given by recursive bit-pattern detection. Here, the execution trace itself is treated as a one-dimensional candidate space of particles, bypassing the need for an explicit geometric mapping.
In this view, elementary particles are defined as short, highly repeated substrings. Composite particles are formed recursively by concatenating previously stabilized patterns; a composite structure is recognized if it appears frequently within the execution trace and if its constituent sub-patterns are already verified particles.
This recursive pattern-matching approach captures the emergence of matter purely from informational redundancy, independent of any explicit spatial embedding. The structural hierarchy is constructed strictly bottom-up: from frequent substrings (elementary particles), to composite concatenations (atoms), to repeated higher-order motifs (molecules).
It should be noted that both of these filters are deliberately minimal and arbitrary. However, they preserve two key scale-invariant features characteristic of our real universe: (i) the hierarchical nesting of matter, and (ii) the physical fact that particle sizes do not expand with the universe—only their mutual distances increase.
By counting the number of recursive particles at each successive entropy level, we observe a striking phase transition. While zero entropy yields absolutely no detectable structures, higher entropy states give rise to an exponentially growing population of emergent particles whose relative abundances follow a distinctive lognormal-like distribution.
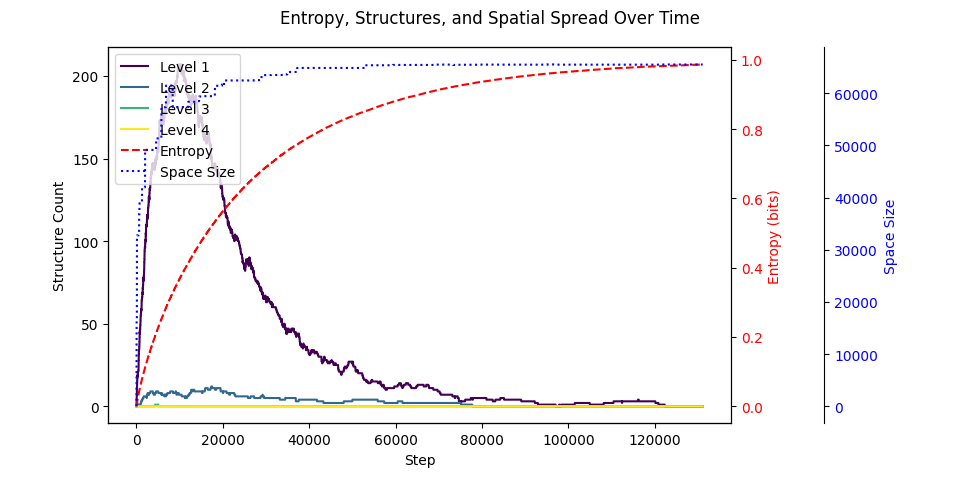
The simulation reveals three key properties:
At zero entropy, the spacetime geometry collapses completely to a single point, and no elementary particles can exist—this is the informational analogue of the initial singularity.
As entropy is introduced, the spatial geometry unfolds exponentially.
At higher entropy thresholds, elementary particles, atoms, and molecules emerge in cascading successions, with their cumulative counts tracking a lognormal trend.
This model sits at the intersection of statistical mechanics, chaos theory, and the Self-Sampling Assumption of the anthropic principle. By assuming only that entropy increases and that observers apply structural filters to identify emergent patterns, a surprising number of cosmological properties emerge natively.
The model is philosophically appealing because it drastically minimizes metaphysical overhead. If the structured universe we observe is simply the most statistically probable outcome within an unguided configuration space, we remove the need for fine-tuned creative mechanisms. It happens simply because it is mathematically likely to happen. Under this framework, one could define any arbitrary filter and compute the direct probability for that specific structure to emerge out of raw noise. This represents a highly compelling, minimalist approach to a foundational Theory of Everything.
Across multiple independent mappings, decoding schemes, representations, and threshold choices, the abundance of emergent structures consistently follows a lognormal distribution.
In physics, lognormal distributions arise generically in systems governed by multiplicative stochastic processes, where growth proceeds through successive random amplifications rather than additive increments. This signature is observed throughout our actual universe, dominating phenomena such as cosmic particle clustering, galaxy mass distributions, biological growth rates, and socio-economic network hierarchies.
One of the deepest mysteries in modern science is why the fundamental laws and constants of physics appear to be meticulously fine-tuned to allow the existence of complex life.
If we model ourselves as one of these emergent substrings waiting to be found within the totality, where should we expect to locate ourselves? The answer is dictated by measure concentration: we should find ourselves near the peak of the lognormal curve, where the probability of emergent structures is highest. From this perspective, the observed regularity, scale hierarchy, and apparent fine balance of our universe are entirely unsurprising. They are merely the most typical properties of a populated configuration space.
The early universe is widely recognized to have inhabited a state of extraordinarily low thermodynamic entropy—a pristine condition that establishes the cosmological arrow of time and drives the evolution of macroscopic systems (Penrose 2010; Carroll 2010). Standard physics emphasizes that this initial order is essential for the subsequent emergence of structure (S 1988; Hawking and Penrose 1996), yet it treats this low-entropy boundary condition as an unexplained, fine-tuned miracle.
Standard physics often points to the Heisenberg uncertainty principle and primordial quantum fluctuations to explain away perfect initial order. But doing so assumes the prior existence of quantum mechanics. What, then, gave rise to quantum mechanics itself?
Our information-theoretic perspective resolves this by treating spacetime geometry as a direct projection of information maximizing its entropy. An expanding universe and an increasing entropy budget are not separate phenomena; they are two sides of the exact same coin. Spatial expansion is merely the geometric translation of statistical relaxation. Our simulations demonstrate that an initial state of precisely zero entropy naturally gives rise to a rich, expanding, hierarchical reality without requiring fine-tuned initial parameters.
According to standard inflationary cosmology, the universe underwent an exponential phase of hyper-expansion during its earliest micro-moments to resolve the flatness and horizon problems. In our model, this inflationary phase is naturally accounted for: the rapid, initial expansion is the geometric interpretation of a system explosively relaxing from a state of maximal, zero-entropy constraint into its initial states of disorder.
When tracking the total number of emergent motifs, the geometric interpretations of information do not yield a perfectly uniform, flat spacetime. Symmetries within the bitstrings cause data to naturally cluster.
These clusters create local entropic gradients, directly biasing the spatial distribution of emergent structures. This provides a highly intuitive explanation for the fundamental nature of gravity: structures naturally drift toward regions of higher statistical weight because those configurations simply contain more available microstates. To put it in terms of entropic gravity: we do not experience a gravitational "pull" toward a massive object; rather, we experience a macroscopic statistical drift because there are simply more ways for our informational structure to exist down there than up here (Verlinde 2011).
Despite these compelling features, our current exploratory model suffers from several profound structural flaws.
While complex motifs do emerge within the model, they fail to evolve smoothly along the continuous geodesics of a stable spacetime.
Instead of yielding elegant spiral galaxies or planets tracing predictable elliptical orbits, our simulation produces a chaotic, erratic "explosion" of information. No smooth General Relativity emerges, and there is no trace of a coherent, unifying quantum wavefunction. What we observe instead are transient, stochastic fluctuations that disintegrate haphazardly, obeying global statistical gradients rather than the strict, local regularities of physical law.
This stands in stark contrast to empirical reality: our universe overwhelmingly favors large, lawful, persistent structures over isolated, chaotic fluctuations.

One could attempt to invoke the Weak Anthropic Principle to explain away this chaos, arguing that we simply find ourselves within one of the incredibly rare, perfectly smooth, and lawful configurations hidden inside the noise because life cannot form within a chaotic explosion.
While this selection effect explains why our observations are conditioned on our survival, it leaves the framework with virtually zero predictive power. It turns the theory into a tautology rather than a predictive mathematical framework.
Why do we find ourselves trapped in a forward-running arrow of increasing disorder and an expanding universe, rather than a contracting one?
We may owe our very existence as reasoning agents to this entropic increase. In semi-hostile environments where structures naturally decay, intelligence functions as a highly specialized local filter designed to "fight back" by actively generating local order (Nicolis and Prigogine 1977).
Intelligence could not function in a universe with a decreasing entropy budget where systems naturally drift toward perfect order on their own. We sustain our local metabolic loops by consuming low-entropy fuel—such as the highly ordered structure of a banana—and breaking that order down into high-entropy waste.
To maintain an identity in a time-reversed, decreasing-entropy universe, our metabolism would be inverted: we would be forced to harvest metabolic waste from our environment and, through some miracle of reverse-biology, assemble it internally to excrete a perfectly formed, low-entropy banana. While mathematically permissible within the configuration space, our forward-running universe is vastly more causally coherent. We are exceptionally lucky to live on the side of the entropic curve where breakfast goes in as order and leaves as waste, rather than the other way around.
If our foundational axioms are correct, then an observer like Alice must emerge from this noise. Yet, our raw statistical simulations fail to capture her. The exact probability that a complex observer—complete with Einstein’s field equations, quantum mechanics, and a continuous, deterministic wavefunction—would spontaneously crystallize out of a purely random bit-flip mutation is practically zero.
Either we are on the wrong track, or we are missing something.
The most crucial realization from our black hole and Big Bang simulations lies in the nature of the "filters" used to detect emergent microstructures. To put it intuitively: given a sufficiently vast sea of raw information and a specific filter, you will inevitably find whatever it is your filter is designed to look for.
If you filter for shapes, you will find geometries. If you filter for substrings, you will find patterns. Are we, as conscious observers, nothing more than self-emergent, self-referential filters?
To test the idea, let us go through two minimal thought experiments.
Imagine a miniature universe composed entirely of coins, and let us define the observer Alice not as a specific piece of metal, but as a structural relationship: any adjacent pair of coins consisting of one Head and one Tail (HT or TH).
Suppose this universe consists of exactly two coins. We toss them repeatedly to build a statistically significant dataset to answer a fundamental question: What is the probability that Alice exists?
The sample space of all possible configurations for a two-coin universe contains exactly \(2^2 = 4\) states:
\[\Omega = \{\text{HH}, \text{HT}, \text{TH}, \text{TT}\}\]
Out of these four possible ways the universe can be arranged, exactly two configurations (\(\text{HT}\) and \(\text{TH}\)) satisfy our filter for Alice. Therefore, the probability of Alice existing is 50%.
Alice is an equivalence class—a macroscopic identity that remains intact across multiple distinct microscopic arrangements.
Let us scale this logic up to a digital realm. Consider a standard computer monitor displaying a grid of \(W \times H\) pixels. If we randomize every pixel, how many unique ways can this screen be configured to render Alice?
There are several ways an observer structure can manifest on this digital canvas:
The entire screen can be utilized to render a single, hyper-high-resolution Alice.
Alternatively, the screen can be partitioned into four quadrants, displaying four lower-resolution iterations of Alice simultaneously.
Naturally, there is a lower bound to this scaling. At a certain point, if we split the grid too many times, the sub-images run out of available pixels. Resolution drops below the threshold of structural coherence, and Alice is no longer recognizable. For instance, if the screen contains both Alice and Bob, dropping the resolution too low renders them completely indistinguishable from one another—the unique informational boundary separating their equivalence classes collapses into generic noise.
Then What is the probability of Alice finding herself as a single, hyper-high-resolution observer filling the entire frame of the universe?
The answer is vanishingly small. The state space of a high-resolution universe requires an immense, highly constrained string of coordinates. By contrast, there are more ways for a pixel grid to form smaller, lower-resolution, localized structures that still successfully fulfill the minimum criteria for Alice’s existence.
Therefore, by the laws of pure statistical measure, Alice should expect to find herself in a localized, minimal-resolution environment—one that possesses just enough fidelity to preserve her essential predictive and reasoning features, but no more.
But how exactly does the math work out? Let us return to our coin-tossed universe.
Suppose the entire universe consists of a total sequence of \(n\) coins. The total number of possible configurations for this universe is \(2^n\). Every single specific sequence has the exact same baseline probability of occurring: \(1/2^n\).
Now, let us define an observer, Alice, and evaluate how her probability of existence changes based on how much information—how many coins—are strictly required to define her.
The Maximum Description Length (\(n\) coins): Suppose Alice requires every single one of the \(n\) coins in the universe to match one exact, hyper-specific configuration. In this case, only \(1\) out of the \(2^n\) possible universes can host her. Her probability of existence is: \[P(\text{Alice}) = \frac{1}{2^n} = 2^{-n}\] If \(n\) is a large number (like the number of particles in a room), this probability is vanishingly small.
Shortening Description Length (\(n-1\) coins): Now, suppose Alice’s structural filter is slightly shorter. Her essential reasoning features can be fully specified using only \(n-1\) coins. The final remaining coin is a "free variable"—it can spin as either Heads or Tails without disrupting her macrostate. Now, there are \(2^1 = 2\) valid configurations that satisfy the filter. Her probability becomes: \[P(\text{Alice}) = \frac{2}{2^n} = 2^{-(n-1)}\] By reducing the required description length by just one single bit, the probability of Alice existing has instantly doubled.
The Minimal Description Length (\(m\) coins): Let us take this to its logical conclusion. Suppose Alice can be described with only \(m\) coins, leaving the remaining \(k\) coins (where \(k = n-m\)) completely free to fluctuate as random background noise. The number of configurations that contain this short blueprint is \(2^k\). Her total probability of existence scales to: \[P(\text{Alice}) = \frac{2^k}{2^n} = \frac{2^{n-m}}{2^n} = 2^{-m}\]
The probability of an observer existing scales exponentially with the brevity of their description length!
The fewer coins needed to define the rules of Alice’s environment, the higher her probability of existence grows, and it does so at an exponential rate.
How then to maximize the probability of existence of Alice?
By Compressing Her!
This exponential scaling law forces us to redefine the very nature of the observer’s "filter." If the probability of finding oneself in an unguided totality peaks aggressively where description lengths are minimal, then the best filter cannot be a passive detector of raw data.
The filter must be a decompression engine.
To maximize the probability for an observer like Alice to exist, the filter should be more intelligent, to discover maximally compressed informational patterns of Alice from the background noise.
Conclusion, or more like a predicton:
We should expect to find ourselves within a highly compressed structures!
Traditionally, physics has viewed the universe through the lens of continuous equations and calculus. However, our previous thought experiments suggest a radical alternative: the universe is not composed of physical “stuff” like particles, but of discrete information—bits.
If the laws of physics emerge from bits via decompression, then we landed in the world of computation and computers. Our most powerful analytical tool is no longer a telescope, but a computer. Under the Church-Turing Thesis, there is a fundamental equivalence between mathematics and computation. Whether we use the abstract tape of a Turing machine or the silicon circuits of a modern PC, the underlying logic remains identical.
There is a theory called Algorithmic Information Theory (AIT), pioneered in the 1960s by Ray Solomonoff, Andrey Kolmogorov, and Gregory Chaitin. AIT shifts the focus from what a system is to the absolute computational work required to describe it.
Traditionally, physics uses Shannon entropy to quantify uncertainty. However, Shannon’s entropy is strictly a statistical measure: it tells you how surprising a message is relative to a pre-existing probability distribution of an entire ensemble. It cannot tell anything about the intrinsic information content of a single, isolated object.
AIT fixes this. Instead of analyzing infinite ensembles, it asks a beautifully simple question about individual objects: what is the shortest computer program that can generate this specific data string?
This is exactly what we need: the best compression implies the maximum probability of existence!
The foundational metric of AIT is Kolmogorov complexity. The Kolmogorov complexity \(K(x)\) of a binary string \(x\) is defined as the length of the shortest program \(p\) that, when executed on a Universal Turing Machine (UTM) \(U\), outputs \(x\) and halts:
\[K(x) = \min \{ |p| : U(p) = x \}.\]
Intuitively, \(K(x)\) measures the absolute compressibility of an object: A highly ordered structure—like a crystal lattice—has incredibly low Kolmogorov complexity because a very short program can generate it (e.g., “repeat this unit cell \(N\) times”). A completely random string cannot be compressed; it contains no patterns, meaning its shortest description is the string itself.
The ultimate bridge between information theory and physical existence is established by the Levin–Chaitin Algorithmic Coding Theorem. If we imagine generating programs by flipping fair coins (random inputs) and running them on a universal machine, the probability \(P(x)\) of a specific output \(x\) emerging is mathematically locked to its complexity:
\[K(x) \approx -\log_2 P(x) \quad \text{or} \quad P(x) \sim 2^{-K(x)}\]
This relationship proves that simplicity, probability, and compressibility are mathematically equivalent. Shorter programs contribute exponentially more statistical weight than longer ones.
This provides an airtight, formal mathematical proof for our coin and pixel thought experiments: objects with short, elegant, recursive descriptions are exponentially more likely to spontaneously manifest than chaotic, uncompressible noise.
To test the compression idea, let us apply ZIP compression (the closest thing to ideal Kolmogorov) to our big-bang simulations. We run the simulations many times, compress them and then pick those that compress the best. What do we see?
Chaos. No beautiful spiral galaxies. All simulations still consistently yield chaotic noise.
If AIT mathematically guarantees that simple, compressed universes are exponentially more probable than random ones, why does our Big Bang simulations still end in a chaotic explosion of Boltzmann noise? Why don’t realistic physical laws—such as General Relativity or basic planetary motion—spontaneously crystallize out of minimal description length?
The standard Kolmogorov complexity suffers from two fatal, foundational flaws that prevent it from being the compression system of the universe:
First, it is discrete. ZIP compression is discrete. Even small changes in its input may yield big jumps in the compressed file size. Can any physics based on such a shaky, non-continuous behavior?
How could reasoning, predicting and decision making work in the universe in which probabilities jump chaotically based on how individual bits happen to be arranged? This is in strike contradiction with our earlier conclusions (Alice as Equivalence class).
Another problem is that Kolmogorov complexity is not even computable. Due to its reliance on the halting problem, \(K(x)\) is fundamentally uncomputable. There is no algorithm that can take an arbitrary string and calculate its exact minimal program length. It can only ever estimate upper bounds - the best possible theoretical compression one can ever hope to achieve with computers.
AIT tells us that a ’simple’ universe is more likely, but the search space of all possible short programs is infinite, good luck with that!
What is the deep, foundational nature of Quantum Mechanics and its mysterious wavefunction?
At its core, the microscopic building blocks of our universe are astonishingly simple—a small, elegant set of quantum fields characterized by just a handful of fundamental parameters, yet capable of producing an enormous expanse of emergent richness.
The complex-valued amplitudes in the wavefunction do all the heavy lifting. Crucial phenomena such as interference, entanglement, quantum tunneling, and superpositions are not separate arbitrary features; they are the mathematical consequences of reality existing within a complex-valued Hilbert space.
If we temporarily step back from these specific technical features, a deeper, more primitive question remains: Why does everything at the subatomic level appear to behave like a wave in the first place?
Consider a conventional MPEG-compressed digital movie. Each individual frame is fundamentally composed of discrete, static pixels. If we were conscious observers made of pixels living entirely inside such a digital movie, what would we perceive as our "laws of physics"?
We would observe that our constituent pixels follow mysterious, abstract, yet completely deterministic wave-like patterns across time. To a pixel-physicist, these transitions would look like fundamental laws. In reality, these patterns are merely the mathematical output of the Discrete Cosine Transform (DCT) or Fourier transforms—the underlying mathematical tools that MPEG codecs use to compress raw pixel grids into a maximally dense format for efficient transmission and storage.
From this informational perspective, the Quantum Mechanical wavefunction is simply an advanced, complex-valued version of the sinusoidal building blocks used in JPEG or MPEG algorithms. Just as a spatial Fourier transform spreads concentrated image information across a spectrum of frequency coefficients, the wavefunction distributes probability amplitudes across basis states in Hilbert space.
Waves—and complex-valued amplitudes in particular—are exceptionally efficient at densely encoding relational information. They produce exactly the kind of spatial smoothness, structural continuity, and predictive regularity that intelligent observers require to exist and reason.
The evolution of the wavefunction itself is entirely deterministic; randomness emerges only when a macroscopic observer attempts to interpret this smooth, continuous wave in terms of discrete, localized particles.
Consider a 3D graphics engine rendering a perfectly smooth, analytically defined sphere with an intended shading intensity of exactly \(0.85\). If the underlying display hardware is strictly limited to discrete integer outputs of either \(0.8\) or \(0.9\), it lacks the structural resolution to render the true value directly. To compensate, the software employs dithering—a probabilistic rendering rule that distributes discrete values across adjacent pixels such that the average intensity across the surface mathematically approximates the ideal fractional value, smoothing out jagged banding and moiré patterns.
In this light, a quantum superposition state: \[|\psi\rangle = \alpha |0.8\rangle + \beta |0.9\rangle\] can be viewed as nature’s highly advanced, complex-valued implementation of this exact computational optimization.
Just as digital dithering maximizes perceived visual quality while minimizing hardware memory consumption, the Born Rule allows the universe to maintain a high-fidelity, compressed informational state within a physical framework operating under strictly limited observables. Quantum mechanics may simply be the most efficient rendering engine mathematically possible—using complex-valued probability amplitudes to maximize the fidelity of the universe with a minimal expenditure of underlying data.
As we established in Chapter 29, standard Kolmogorov complexity provides a beautiful theoretical foundation for minimal description lengths. However, because it relies on the binary halting state of a Turing machine, it is fundamentally discrete, discontinuous, and uncomputable. It is difficult to see how such a jagged, "jumpy" informational measure could smoothly support stable prediction, continuous spacetime geometry, or the gradual evolutionary reasoning of an intelligent observer.
More importantly, observational evidence suggests that physical systems already possess a natural, inherent mode of information representation: their decomposition into spectral modes. This motivates us to replace abstract algorithmic complexity with a physically grounded, continuous alternative:
Definition 30.1. Spectral Complexity The total informational cost required to uniquely specify the amplitudes, frequencies, and phases of the spectral modes composing a physical state.
According to the Solomonoff Prior, the probability \(P\) of a given state manifesting is exponentially inversely proportional to its descriptive length \(L\): \[P(s) \approx 2^{-L(s)}\]
As our previous thought experiments demonstrated, this style of exponential selection operates on any valid informational measure, not just raw binary code. When we swap out Kolmogorov complexity for Spectral Complexity, high-frequency "noise" and infinite-mode configurations become so spectrally expensive that their probability of manifestation instantly vanishes.
In other words, we do not find ourselves in a chaotic, infinitely complex universe because the information required to describe our macrostate can be arranged far more efficiently as a compressed wavefunction. The simplest, most highly compressed spectral descriptions of our state possess the highest statistical measure, and consequently, are the exact states in which we are most likely to discover ourselves.
To test the validity of this Compression Hypothesis, we simulated a discrete bitstring starting from a zero-entropy state and allowed it to evolve toward equilibrium. However, instead of evaluating it as raw bits, we forced the system to interpret and project the data through a compressed, complex-valued wavefunction representation.
According to our modified principles of Solomonoff induction, the structural weight of any given configuration is determined strictly by its compressibility under this spectral filter. Therefore, the most compressible configurations—those defined by law-like regularity, wave-mechanics, and geometric symmetry—completely dominate the probability landscape.
To implement this, we introduce a ‘spectral_complexity()‘ method to our underlying Wavefunction simulation class. The complexity is determined by counting the total bits required to instantiate the state’s constituent modes. The total spectral complexity \(C_s\) of a state \(\Psi\) is calculated as the sum of its algorithmic software overhead and the explicit parameters of its \(N\) active modes:
\[C_s(\Psi) = \text{Cost}(\text{base}) + \sum_{i=1}^{N} \left[ \text{Cost}(\phi_i) + \text{Cost}(A_i) + \log_2\left(\frac{\omega_i}{\Delta\omega}\right) \right]\]
Where:
\(\text{Cost}(\text{base})\): The constant \(O(1)\) computational cost of the underlying trigonometric and mathematical subroutines (e.g., the ‘sin()‘ method). On a universal cosmological scale, this overhead is fixed and treated as a constant.
\(\text{Cost}(\phi_i)\): The explicit bit-cost of encoding the wave phase. Because phase is strictly bounded within the periodic interval \([0, 2\pi]\), this is modeled as a small, fixed-width bit cost per active mode.
\(\text{Cost}(A_i)\): The informational bit-depth required to encode the continuous amplitude.
\(\log_2(\omega_i / \Delta\omega)\): The dominant term of the cost function. This represents the exact number of bits required to specify the mode frequency \(\omega\) relative to the system’s minimum resolution threshold \(\Delta\omega\).
It should be noted that this formulation represents our initial toy candidate for a spectral metric. While different precise digital encoding schemes are possible depending on how one compresses the wavefunction, they all fundamentally share a critical mathematical property: they assign a smooth, continuous cost gradient across neighboring physical states.
Compared to our initial "Something out of Nothing" simulations—which lacked a spectral filter and invariably collapsed into a chaotic explosion of Boltzmann brains—the introduction of the spectral cost function completely shifted the evolutionary dynamics:
Emergence of Spacetime Smoothness: The chaotic, high-entropy white noise of the baseline simulation was instantly suppressed and replaced by smoothly evolving, wave-like spatial profiles.
Spontaneous Geometric Symmetry: Symmetric geometric wave packets and highly interconnected, net-like structural lattices emerged natively as the most probable, mathematically dominant outcomes.
Predictability as Measure: The simulation formally confirms that lawful, regular universes are not fine-tuned anomalies of chance. Instead, they represent the most compressible, data-efficient, and therefore highly probable configurations existing within a timeless informational superposition.

These findings strongly indicate that the wave-like nature of our microscopic world is not an inexplicable, quirky preference of physics. It is the definitive algorithmic signature of a highly optimized data-compression scheme.
By replacing the uncomputable, discrete Kolmogorov metrics of standard AIT with a continuous, computable framework of Spectral Complexity, we establish an explicit mathematical bridge between physical structures and informational descriptions. Algorithmic induction explains why we inhabit a predictable, smooth universe governed by strict symmetries rather than existing as fleeting, chaotic fluctuations: order is simply easier to compute than chaos.
The cosmos waves because we are observing highly compressed structure. The wavefunction is not a mysterious physical entity; it is the universal compression algorithm of reality.
The Wavefunction Compression Principle (WCP) The quantum wavefunction is the universe’s native data-compression scheme. Physical reality manifests along the gradients of maximum compressibility.
From zero entropy to thermal equilibrium, an evolving system can trace an almost infinite variety of trajectories—the vast majority of which represent nothing but useless, chaotic noise. We utilize an AI optimization layer to isolate the specific historical paths that maximize "compressibility"—the tracks displaying deep hidden symmetries and recurring structural motifs.
When we randomly sample these optimized histories, chaotic noise never manifests. By filtering for absolute informational efficiency, these simulations confirm that structural order is not a rare accident of cosmological fine-tuning, but the statistically dominant feature of a compressed universe.
Microscopic reality appears wave-like.
Fine. We now understand why.
But observers do not inhabit Hilbert space.
They inhabit geometry.
Why?
Let us recall our hourglass metaphor. There exists an astronomical, near-infinite number of ways to microscopically arrange individual grains of sand inside the lower chamber of an hourglass. Yet, despite this massive underlying microstate entropy, every single one of those chaotic configurations yields the predictable macroscopic geometric structure: a simple, uniform cone shaped stack of grains.
The physics of the hourglass acts as a spatial compressor - it compresses billions of independent, messy degrees of freedom into a geometric shape uniquely described by just a couple of macroscopic variables.
With sufficiently many grains, a small set of macroscopic constraints naturally generates simple large-scale geometries such as spherical planets.
To scale this logic to its absolute limit: given a \(3+1\) dimensional spacetime manifold, what is the highest possible compression efficiency a physical system could ever theoretically achieve?
The answer is a black hole.
The physics of black hole entropy represents the ultimate geometric data compression routine. One can throw any arbitrary arrangement of matter, information, or complex structures into an event horizon—guitars, spaceships, or burning stars—and the geometry instantly strips away their uncompressed, high-entropy descriptive overhead. What remains is a perfectly smooth, featureless region of spacetime governed by the No-Hair Theorem, fully specified by exactly three macroscopic attributes: mass (\(M\)), electric charge (\(Q\)), and angular momentum (\(J\)).
If the quantum mechanical wavefunction acts as nature’s spectral compression system, then what purpose does GR serve?
The answer is: compression.
Geometry has a job!
Under an information-theoretic framework, the both theories appear to be compression algorithms optimized for different informational domains, unified by a single imperative: the minimization of absolute description length.
Rather than encoding probability amplitudes across abstract configuration spaces, General Relativity encodes the causal and relational structure as geometric spacetime.
From the Chapter we recall that in GR physical force is replaced by smooth manifold curvature, and localized acceleration under interaction is replaced by inertial motion along geometric geodesics.
General Relativity, at its core, appears as a highly advanced geometric compression scheme designed to encode the relational, causal matrix of the cosmos.
Dispite their differences, when evaluated through the lens of compression, Quantum Mechanics and General Relativity reveal many structural symmetries that standard physics treats as mere mathematical coincidences.
In Quantum Mechanics, observables emerge from operators acting on a Hilbert space. In General Relativity, gravitational structure emerges from invariant relations encoded in spacetime geometry. In both domains, stable physical content is defined by structures that survive changes of representation.
Neither theory stores absolute, localized information. Quantum Mechanics explicitly encodes the mathematical relations between measurement outcomes via complex probability amplitudes. General Relativity explicitly encodes the topological relations between events via the metric tensor of a spacetime manifold. In both systems, absolute, privileged reference frames are utterly discarded and replaced by pure relational networks.
Both architectures are strongly governed by global constraints. Unitarity in Quantum Mechanics preserves the conservation of total probability over time. In General Relativity, the Bianchi identities and the Einstein field equations tightly constrain how curvature can dynamically evolve.
If both frameworks are fundamentally interpreted as dual regimes of information compression, their divergence lies not in their underlying philosophy, but in the specific informational domains over which their compression operates:
Quantum Mechanics compresses the configurational possibility space of a system.
General Relativity compresses the causal-geometric space of a system.
The historical struggle to quantize gravity arises from a category error: attempting to force the mathematical language of possibility space into the mathematical language of realization space. In truth, both theories are distinct, optimized projections of a more primitive, underlying informational substrate.
Why would nature implement two separate compression systems?
Why did nature favor Geometric Einstein over Spectral Hilbert for our macroscopic reality?
As concluded in the Chapter , intelligence and conscious observation strictly requires an absolute informational boundary—a clean, distinct separation between the observer and the external environment.
As conscious agents, we are fundamentally finite informational structures. We cannot exist as diffuse, fluid, overlapping gradients. Observers require stable subsystem boundaries preserving internal state coherence across time. If two highly complex, entangled informational systems (such as two humans) were to spatially overlap and mingle their states in a high-dimensional Hilbert space, their internal data organization would instantly disrupt, causing immediate decoherence and a catastrophic loss of structural identity (death).
To calculate and maintain such a boundary within a high-dimensional, fully entangled Hilbert space is computationally devastating, requiring an unsustainable expenditure of information.
However, boundaries can be defined very economically within a low-dimensional geometric space!
Geometry grants us the gift of locality. It establishes the rigid, unyielding distinction between ‘here’ and ‘there,’ between ‘me’ and ‘the rest of the universe.’
The long-sought unification of physics is not achieved by violently forcing the linear mathematics of Quantum Mechanics into the non-linear tensors of General Relativity. Instead, it is achieved through Compressibility.
A purely spectral representation provides no native notion of localized boundary, inside versus outside, or persistent subsystem separation. Observers require such structures.
Because there exist enormously many ways to interpret a single wavefunction as geometric spacetime, the question naturally arises: in which spacetime geometry are observers most likely to find themselves?
The answer is, the one that dominates the measure.
As established in the Chapter , the generalized principles of description length driven induction, simpler descriptions possess exponentially higher statistical measure (\(2^{-K}\)).
We inhabit geometric spacetime because observer-compatible geometries offer exceptionally low description length for maintaining stable informational boundaries, thereby dominating the statistical measure.
Suppose we possessed a complete physical description of the universe: every particle state, every quantum amplitude, every bit of information.
Would meaning (semantic) automatically follow?
No!
A raw informational structure does not announce what it represents.
The same finite configuration may be interpreted as a number, a computation, a universe, random noise, or nothing at all.
Semantic underdetermination is the problem.
The interpretation itself has become the mystery.
Consider Alice using a decimal system, motivated by biological convenience (ten fingers): \[2 + 3 = 5.\]
Bob, working in a computational environment, adopts binary representation:
\(2 \rightarrow 10_2\)
\(3 \rightarrow 11_2\)
\(5 \rightarrow 101_2\)
In binary arithmetic the same relation becomes: \[10_2 + 11_2 = 101_2.\]
If Alice encountered Bob’s notation without context, she would misinterpret the symbols. In particular, \(10_2\) does not refer to ten. Even the full expression requires an assumed encoding scheme. Thus, meaning is not intrinsic to the symbol structure alone, but depends on an interpretive convention.
The arbitrariness of representation becomes clearer when we replace the digits entirely. The binary alphabet \(\{0,1\}\) may be replaced with coin faces \(\{H,T\}\): \[HT + HH = HTH.\]
Operational symbols such as \(+\) and \(-\) are likewise part of a chosen syntactic convention, not intrinsic to the underlying relation.
In finite digital systems, identical bit patterns admit multiple semantic interpretations. For an 8-bit word:
\(11111111\) may represent \(255\) in unsigned interpretation,
or \(-1\) in two’s complement representation.
The physical state is identical; only the interpretation differs.
Even ordering conventions are not intrinsic. A bitstring such as \(001\) may correspond to different values depending on bit significance:
left-to-right (MSB first): \(1\),
right-to-left (LSB first): \(4\).
These are merely two of the \(n!\) possible permutations of bit significance.
Consider a computer in full physical detail. A memory dump yields only a finite sequence of bits. The CPU, instruction set, and storage devices are themselves physically instantiated information structures. At the level of raw physical state there is no intrinsic separation between “code” and “data”. This distinction arises solely through an interpretive layer.
The global state of an \(n\)-bit system occupies a configuration space of size \(2^n\). Computation, or any other semantics, arises only from relations between states under a chosen interpretive rule.
A raw bitstring does not intrinsically contain logic, syntax, semantics, truth conditions, or consistency relations. These arise only after selecting an interpretive scheme.
As the number of bits increases, the space of possible interpretations grows combinatorially. A single finite configuration admits a vast number of syntactically valid decompositions into code/data partitions, memory layouts, instruction interpretations, and execution histories.
While the state space itself contains only \(2^n\) configurations, the number of possible transition functions is \((2^n)^{2^n}\). For \(n=3\) bits this is already \(8^8 = 16\,777\,216\). For \(n=10\) the number has thousands of digits.
This vast explosion of possible interpretive rules implies that neither a “Universe” nor a “Computer” can be regarded as fundamental in isolation — the interpretive rule space grows enormously faster than state space.
Even after an interpretation is assigned, it is not unique. Different interpretive schemes may preserve the same underlying relational structure.
Physics has already encountered this problem.
Different mathematical descriptions often represent the same underlying reality.
In mathematical physics, when a physical state remains unchanged under a change of local descriptive frameworks, we call that symmetry a gauge invariance.
Consider a sufficiently large bitstring. Under one interpretation it may appear as random noise. Under another it may be interpreted as implementing the relation \(2 + 3 = 5\), as encoding a mathematical structure, or even as the informational substrate of an observer. Instruction layouts, memory partitions, addressing schemes, and representational conventions may all vary, yet certain structural relations can remain invariant across these transformations.
We therefore define:
Two interpretations belong to the same interpretive equivalence class if they preserve the same observable relational structure under admissible transformations.
What ultimately matters is not the precise arrangement of symbols, but the invariant relational structure that survives reinterpretation: \[\text{information} \ \longrightarrow \ \text{interpretation} \ \longrightarrow \ \text{relational structure (invariant)}\]
This relational structure is more primitive than computation, mathematics, or any particular semantics. All of these are merely possible interpretations.
For example, when humans interpret the output of a computer monitor, they rely on an astronomical stack of shared conventions (encoding standards, pixel geometry, scan order, handedness, row length, etc.). Changing these conventions can render the identical underlying data unrecognizable or meaningless.
By synthesizing the semantic nakedness of raw data with the mathematical necessity of gauge invariance, we arrive at the foundational thesis of this framework:
Theorem 32.1 (Interpretive Gauge Invariance Thesis - IGIT). Ontological and physical significance cannot reside in representational labelings. Because raw informational structures possess no intrinsic semantics (Axiom of Semantic Non-Intrinsicality), all physical laws and properties must be invariant under a change of interpretive framework.
This leads directly to the overarching system property of our universe:
Self-Interpretive Information Principle (SIIP) siip The raw informational substrate is semantically silent.
Within this silent substrate exists a vast landscape of possible interpretive frameworks, equivalence classes, and self-locating observers.
Though profoundly distinct from classical structural frameworks, the concept of a self-locating observer is firmly established in anthropic physics and decision theory. Instead of asking ’Why does this specific universe exist?’, a self-locating observer asks: ’Given that all possible configurations exist mathematically, which specific slice of them am I currently observing?
The preceding analysis allows us to revisit and resolve Eugene Wigner’s famous puzzle concerning the “unreasonable effectiveness of mathematics in the natural sciences.”
Mathematics is effective not because the physical world possesses intrinsic mathematical properties, nor because abstract mathematical objects inhabit a Platonic realm with causal influence on matter. Instead, its effectiveness arises from the highly selective action of intelligent observers (interpreters).
A raw information structure — whether a bitstring, a physical state, or the configuration of the universe itself — admits an astronomically large space of possible interpretations. Within this space, only a vanishingly small subset consists of stable, coherent, predictive, and intersubjectively shareable relational structures. Mathematics is precisely this privileged slice.
Intelligent observers do not passively discover pre-existing mathematical truths. They actively function as interpretive filters that select, stabilize, and commit to specific equivalence classes within the vast interpretive landscape. What we call “physical law” emerges when these selected mathematical structures align tightly with the relational invariants of observed phenomena.
This perspective dissolves the apparent mystery. The effectiveness of mathematics is reasonable once we recognize that:
The underlying information is semantically silent and interpretationally prolific.
Observers themselves are self-interpreting structures that have evolved or emerged to privilege those interpretations yielding survival-relevant predictability and consistency.
Different observers (or the same observer under different conventions) can extract entirely different mathematics from the same raw information, yet certain deep structural correspondences remain robust across wide classes of interpretations.
Thus, mathematics works so well because we are exceptionally good at finding and fixing those rare interpretive schemes that map the invariant relational skeleton of reality onto compact, powerful, and communicable symbolic systems. The universe does not need to be mathematical. It only needs to be sufficiently rich in information to admit the interpretive filters that observers naturally apply.
In this light, the “unreasonable effectiveness” is revealed as an anthropic-like selection effect operating within the enormous space of possible interpretations of self-interpretive information.
Thus, neither mathematics nor computation are fundamental properties of information itself, but emergent relational structures arising between informational configurations.
This relational view is fundamentally incompatible with the Platonic paradigm. Reality requires no pre-existing mathematical realm; mathematics is the invariant architecture discovered when intelligent observers map the silent totality.
We are now in possession of all the pieces of our cosmological puzzle. We have established that the quantum mechanical wavefunction compresses the possibility space of our universe through a spectral language (\(C_s\)), while General Relativity compresses its realization space through a geometric language (\(C_g\)).
Because the relationship between these two frameworks is a many-to-many mapping, any given observer wavefunction can be interpreted through nearly infinitely many different geometric spacetime metrics, and conversely, any spacetime manifold can be decomposed into nearly infinitely many different wavefunctions. This creates nearly infinite, multi-dimensional configuration space.
How does nature choose our specific reality from this unimaginably large haystack?
It does so by maximizing global joint probability. In information theory, when a system must be simultaneously validated across two dual representations, its joint probability is the product of its individual probabilities. Therefore, the absolute measure of any emergent physical state (\(s\)) within the totality is given by the Joint Compressibility Equation:
\[P_{\text{joint}}(s) = P_{\text{spectral}}(s) \times P_{\text{geometric}}(s) = 2^{-C_s(s)} \times 2^{-C_g(s)} = 2^{-\left(C_s(s) + C_g(s)\right)}\]
This deceptively simple formula yields a profound variational principle for the ultimate Theory of Everything. Because nature ruthlessly maximizes probability, it must systematically minimize the total description length of its dual scripts. The cosmos is governed by a singular, overarching informational Lagrangian:
\[\label{eq:lagrangian} \mathcal{L}_{\text{info}} = C_s(\Psi) + C_g(g_{\mu\nu}) \longrightarrow \text{Minimum}\]
Neither geometry nor waves are primary; they are equal, co-dependent projections of a single underlying informational matrix.
This explains why our macroscopic universe is so phenomenally stable. If the wavefunction becomes too wildly erratic, it drives up the Spectral Complexity (\(C_s\)), which instantly warps the local spacetime fabric into an astronomically expensive, chaotic Planckian foam, spiking the Geometric Complexity (\(C_g\)). Conversely, if geometry collapses into an uncompressible infinity—such as a classical singularity—the geometric engine runs out of descriptive capacity (\(C_g \to \infty\)), forcing the local wavefunction to collapse into a state of absolute zero data.
Our observed reality is the exact mathematical sweet spot of this joint optimization. Spacetime is smooth and the quantum world is lawful because this specific configuration represents the absolute shortest combined code nature can write. The universe is not made of matter or fields. It is a single, beautifully compressed file, executing the most efficient possible script so that we may exist to read it.
To anchor this abstract architecture into plain intuition, we can utilize a pedagogical thought experiment. Imagine an intelligent observer—say, a liquid-metal Terminator T-1000—living inside a high-fidelity, computer-generated movie.
This universe is rendered frame-by-frame as a 3D video composed of discrete voxels (volumetric 3D pixels). To keep the storage file size manageable, the creators use a sophisticated, complex-valued 3D-MPEG compression codec.
On a macroscopic scale, the T-1000 perceives its world as a smooth, continuous geometric manifold. Everything at this scale appears as perfectly continuous surfaces, modeled with parametric Non-Uniform Rational B-Splines (NURBS) of a high mathematical degree, defined within a Lorentzian signature. The T-1000 navigates this geometric theater flawlessly using the intuitive laws of smooth motion. He feels like Einstein.
Then, the T-1000 decides to become a particle physicist. As it begins to zoom in and probe the absolute limits of its reality, it makes a series of startling discoveries:
The Artifact of Compression: It notices that its seemingly continuous skin is actually composed of discrete, bounded voxels.
The Spectral Signature: It finds that these voxels do not update or change positions randomly. Instead, their coordinates and densities are governed by interference patterns, phases, and frequency coefficients.
The Discovery of Quantum Mechanics: The T-1000 has just "discovered" Quantum Mechanics. It realizes that to accurately model the state of any single voxel, it must use a complex-valued unitary wavefunction.
The T-1000 might naturally ask: “Why do I live in a world of complex-valued waves (Hilbert space) instead of just smooth shapes (Einsteinian space)?” Furthermore, driven by standard reductionist thinking, it might begin developing a monumental \(10^(500)\) Vagua Theory or maybe also Loop Voxel Gravity to mathematically smash the macro-continuum of its world into pieces.
But this is a category error. The T-1000 is simply looking at the compression artifacts of its own reality. The “waves” are not an additional, underlying basement of material complexity; they are the most informationally efficient way to represent and store discrete voxels with minimal code overhead. This does not mean the macro-NURBS should be voxelized. The T-1000’s reality is Einsteinian at the macroscopic scale to maintain clear boundaries, but Hilbertian at the microscopic level to optimize data density.
Quantum Mechanics is not a separate physical foundation upon which gravity is built. Rather, QM is the universal spectral monitor rendering a smooth geometric master-tape into a compressed, finite stream. We see everything “waving” at the pixel scale simply because we are observers living inside a highly optimized bitstream. Trying to quantize smooth geometry to build a theory of everything is merely attempting to find pixels inside an equation.
Our theory begins with minimal assumptions. If reality is fundamentally informational, a natural question arises: Is the total information of the cosmos finite or infinite?
If it were finite, one would have to ask: Finite by how many bits? And who, or what, set that arbitrary threshold? Any fixed binary bound would itself require an external explanation. A finite informational universe merely pushes the mystery of creation back one level.
The only non-arbitrary conclusion is that the deep nature of everything cannot be finitely bounded. At the most fundamental level, reality must be infinite—perhaps not even informational in the familiar sense, but existing beyond any finite baseline description. Therefore, we do not presuppose that reality is fundamentally discrete, finite, or governed by prior, external laws.
The only firm starting point we adopt is purely observational: conscious finite observers exist and have structured experiences (including pain, geometry, and pattern recognition).
For formal descriptive purposes, we introduce a finite, static configuration space: \[\mathcal{C} = \{0,1\}^n\] where each \(c \in \mathcal{C}\) is a complete, static snapshot of bits. No spacetime, explicit dynamics, or external laws are assumed. The binary bit is not ontologically fundamental; it is used here strictly as a practical tool for data counting.
Each configuration \(c\) admits multiple potential descriptions \(d \in \mathcal{D}(c)\). We quantify the complexity of a description \(d\) by splitting it into its dual spectral and geometric representations: \[K(d) = K_{\rm spec}(d) + K_{\rm geo}(d)\]
The spectral complexity \(K_{\rm spec}(d)\) measures the informational cost of the wave-like modes: \[K_{\rm spec}(d) = \sum_i \left[ \log_2\left(\frac{A_i}{\Delta A_i}\right) + \log_2\left(\frac{2\pi}{\Delta \phi_i}\right) + \log_2\left(\frac{\omega_i}{\Delta \omega_i}\right) \right]\] where the sum runs over active spectral modes, and the \(\Delta\) terms represent the precision thresholds needed to distinguish states. The geometric complexity term \(K_{\rm geo}(d)\) accounts for the algorithmic overhead of localized spatial structures and boundaries (\(C_g\)). Lower total complexity corresponds to a higher statistical multiplicity, yielding a higher weight in the final induced measure.
The raw algorithmic weight of a static configuration \(c\) is accumulated across all its valid descriptions: \[W(c) = \sum_{d \in \mathcal{D}(c)} 2^{-K(d)}\] This defines our raw baseline probability distribution over the state space: \[P(c) = \frac{W(c)}{\sum_{c'\in\mathcal{C}} W(c')}\]
However, raw configurations possess no intrinsic semantics. A binary sequence carries no inherent meaning until it is filtered. An observer is therefore modeled not as a single configuration, but as a grading semantic functional: \[\mu_O : \mathcal{C} \to [0,1]\] which measures how strongly a given bit configuration realizes a stable, observer-relative structure. This functional induces an observer-relative equivalence relation: \[c_1 \sim_O c_2\] whenever \(c_1\) and \(c_2\) realize the same relational observer structure to within the tolerances encoded by \(\mu_O\).
Much like an astronomical number of microstate arrangements of sand grains yield the exact same macroscopic cone shape, a massive semantic equivalence class of bit configurations instantiates the same observer-state. The observer-conditioned probability then becomes: \[P(c \mid O) = \frac{\mu_O(c)W(c)}{\sum_{c'} \mu_O(c')W(c')}\]
Our core hypothesis is that configurations capable of supporting observers strongly favor smooth, low-frequency spectral content. Sharp, chaotic particle trajectories require massive high-frequency modes, which exponentially spike the description length \(K_{\rm spec}(d)\) and are instantly suppressed by the measure.
As a result, observer-compatible realities are overwhelmingly dominated by configurations exhibiting inertia, smooth curved paths, and law-like behavior. Spacetime geometry emerges precisely because it makes informational boundaries computationally cheap to describe.
Time in this static block-universe is not a fundamental background dimension. It emerges entirely as an internal ordering relation \(\prec_O\) on configurations, where \(c_1 \prec_O c_2\) if \(c_2\) supports a more advanced, stable realization of the observer functional \(\mu_O\). The experienced flow of time corresponds to traversal along the most compressible, optimized paths through this timeless superposition.
As accumulated memory and internal entropy grow, maintaining high compression eventually becomes too computationally expensive; the supporting measure falls below a critical threshold, and the observer’s awareness naturally fades.
\[\text{Raw Information} \longrightarrow \text{Interpretation Space} \longrightarrow \text{Observer Equivalence Classes} \longrightarrow \text{Induced Measure} \longrightarrow \text{Experienced Physics}\]
We can now express the probability of an entire observed history or path \(\gamma\) within the observer-compatible space \(\Gamma_O\): \[\mathbb{P}(\gamma \mid O) = \frac{1}{Z_O} \exp\left(-\lambda\mathcal{C}_O[\gamma]\right), \qquad \gamma \in \Gamma_O\] This states that observed physical laws are simply the large-deviation minimizers of the total informational cost function \(\mathcal{C}_O[\gamma]\) over the set of all semantic paths.
To represent this joint compressibility logic, we introduce the **\(D-\psi-G\) Trinity notation**: \[D \ \longleftrightarrow \ \psi \ \longleftrightarrow \ G\] where each component represents a vital pillar of the compression pipeline:
\(D\) (Data): The raw, naked, uncompressed discrete information of the totality.
\(\psi\) (Spectral / Quantum): The spectral codec that compresses raw possibility space into a smooth wavefunction (minimizing \(C_s\)).
\(G\) (Geometry / Gravity): The geometric codec that compresses realization space into a smooth spacetime manifold with economic boundaries (minimizing \(C_g\)).
The quest for a unified Theory of Everything has historically been framed as a struggle to quantize the macroscopic manifold of gravity, or to uncover the discrete, fundamental "atoms" of spacetime. This work suggests that such a pursuit is a category error. By shifting our perspective from a hardware-centric view of a material universe to an software-centric framework of data compression, we arrive at a natural unification.
The primary realization of this work is that finiteness does not necessitate discreteness. Just as a perfectly smooth, continuous parametric spline can be fully defined by a tiny, finite set of control coordinates, the smooth geometry of General Relativity represents the most informationally efficient description for a stable reality. Quantum Mechanics is not the sub-basement upon which gravity is built; it is the spectral artifacting that arises when a finite observer attempts to sample and render that smooth source.
We conclude with our four core pillars:
The Codec of Nature: Physics is not dictated by external, heavy-handed laws. Reality is the statistical consequence of a joint compressibility measure. We inevitably find ourselves within specific descriptions where the combined cost of spectral representation (\(C_s\)) and geometric realization (\(C_g\)) is globally minimized.
The Artifact of Hilbert Space: The waving nature of the subatomic world is the Nyquist-limit noise of a compressed bitstream. We live in a world of complex-valued waves because frequencies are the most mathematically efficient way to store relational data.
The Internalized Observer: By moving the clock inside the configuration space, we transition from a running process to a static block-universe. Time is not a dimension of space, but the sequential decompression of data by a finite observer functional.
The Smooth Continuum: Attempting to quantize the smooth manifold of General Relativity is like trying to look for physical pixels inside an analytic equation. The resolution of our experience is fundamentally bounded by our informational capacity, but the underlying geometric model remains beautifully smooth.
The ultimate test of the framework developed so far is whether it can generate something that resembles observed reality using only its own principles.
We constructed a minimal proof-of-concept simulation with one central question:
Given only an observer-conditioned spectral compression measure, can anything resembling inertia, interference, or mutual attraction emerge — without being explicitly programmed?
No forces, equations of motion, spacetime metric, or physical laws were hard-coded. The system is a pure informational engine that selects configurations solely according to a joint spectral-geometric complexity measure.
While the framework presented in this book offers a unified informational picture of reality, demonstrating it through direct computational proof-of-concept faces severe practical obstacles.
The core difficulty is combinatorial explosion. Consider a modest system containing only \(n\) bits of information. The total number of possible raw configurations is already \(2^n\). For \(n = 100\)—a tiny system by physical standards—this yields approximately \(10^{30}\) possible states. Even listing them all would be impossible on any conceivable computer.
The problem grows dramatically worse when we consider dynamics. The number of possible ways to order or traverse these configurations is \((2^n)!\), a number so enormous that it dwarfs even the most extreme quantities in cosmology. For comparison, the number of atoms in the observable universe is roughly \(10^{80}\); \((2^{100})!\) is inconceivably larger. This is super-exponential growth, rendering brute-force enumeration or simulation fundamentally intractable even for laughably small systems.
Yet these figures only describe the raw configuration space.
The true complexity lies in the interpretation space—the vast set of possible semantic mappings that can be applied to the same binary data. Pure bits carry no inherent meaning, ontology, or physical interpretation. A given string of 0s and 1s can, in principle, be decoded as a wavefunction, a spacetime geometry, a conscious observer, or sheer noise, depending on the chosen descriptive language. The number of reasonable (and unreasonable) interpretive schemes is itself effectively unbounded. Each interpretation then carries its own spectral complexity \(C_s\) and geometric complexity \(C_g\), which must be evaluated under the joint compressibility measure.
This creates a double-layered explosion: an astronomical space of raw configurations, multiplied by an even larger space of valid descriptions and observer functionals.
Direct simulation of the full framework is therefore not merely difficult—it is computationally impossible with any realistic resources, now or in the foreseeable future.
Fortunately, brute-force enumeration is not the only path forward. Just as we do not need to simulate every possible fluid molecule to understand aerodynamics, we can seek clever approximations, analytical limits, observer-centric selection principles, and targeted numerical experiments on small but representative subsystems.
For the above mentioned reasons, and since any full biological observers are computationally intractable, we use a simplified proxy: a localized Gaussian wave packet with limited internal memory — essentially a small, coherent “Gaussian blob”. The size and memory capacity of this blob are adjustable parameters.
The simulation explores possible “observer walks” (sequences of configurations consistent with the persistence of this blob) and selects them according to the induced observer-conditioned measure \(P(c \mid O)\).
A complex-valued wavefunction class is implemented, with method to compute spectral complexity from frequencies, amplitudes, and phases. Geometric complexity is approximated through a linearized measure of curvature and boundary sharpness.
A Metropolis-Hastings sampler explores the configuration space, guided exclusively by the minimization of total spectral-geometric description length.
To test whether the joint compressibility framework can produce realistic physics, we started with a minimal 2+1D simulation. The goal was simple: start with pure randomness and see whether anything resembling inertia, wave interference, or mutual attraction would emerge when configurations are selected solely based on how easily they can be compressed.
The simulation works as follows:
At its foundation is a random noise substrate — a sea of particles whose positions are continually redrawn from a probability distribution. This distribution is generated by the interference patterns of complex-valued wavefunctions, similar to how quantum mechanics describes reality.
Within this noisy environment, observers are modeled as localized Gaussian wave packets — essentially smooth, coherent “blobs” of information. Each blob represents a simplified observer with limited memory and internal structure. These observers do not follow pre-programmed laws of motion. Instead, at every step, the system evaluates many possible small changes to their trajectories and selects those that minimize the total spectral and geometric complexity (\(C_s + C_g\)).
This implements the core principle of the framework: the more compressible an observer’s experience is, the more statistically likely it becomes. Smooth, predictable motion compresses far better than erratic, high-frequency jitter. As a result, the observer-blobs naturally develop inertia — they prefer to continue moving in gentle curves rather than making sudden turns, because sharp changes create expensive high-frequency components in the wavefunction.
Quantum-like behavior emerges directly from the complex-valued wavefunction representation. Interference patterns appear naturally, without being programmed.
Emergent mutual attraction (a primitive form of gravity) arises because overlapping wavefunctions between nearby observers create regions of higher probability density in the space between them. The observers are statistically “pulled” toward areas where more microscopic configurations support their persistence.
No forces, no equations of motion, and no spacetime metric were ever coded into the simulation. The only rule was: keep the observer’s description as short and compressible as possible.
The simulation is deliberately minimal. It uses a few thousand particles on a 2D grid and runs for a few hundred time steps. Even with these severe limitations, clear structured behavior consistently appears.


These results suggest that key aspects of classical and quantum behavior can arise purely from informational compression.
Despite these encouraging results, a significant limitation appears. The Gaussian blobs eventually lose their individual identities and merge into a single undifferentiated structure. There is no stable repulsion or exclusion principle at short distances.
In standard quantum mechanics, fermions obey the Pauli exclusion principle due to antisymmetry of the wavefunction. In our pure compression-based approach, symmetric (bosonic) configurations are strongly preferred because they allow shared spectral modes and lower total description length. Antisymmetric configurations appear significantly more expensive and are therefore suppressed.
Hard-coding antisymmetry would violate the spirit of the project. Finding a natural mechanism within the compression measure that makes multiple occupancy of the same state dramatically more costly for coherent observers remains the most important open challenge of the theory.
This proof-of-concept simulation demonstrates that important features of physical law — inertia, wave interference, and weak attraction — can emerge from pure spectral compression and observer conditioning, without being explicitly programmed.
It supports the broader thesis that law-like behavior is not imposed from outside but arises internally as a consequence of how self-interpretive information is most efficiently organized. However, the emergence of stable, distinguishable particles (fermionic statistics) is not yet achieved and constitutes the current frontier.
By applying an observer filter (the Gaussian blob) across all possible configurations and evaluating them under complex-valued Fourier compression (the wavefunction), smooth and symmetric trajectories consistently show the highest compressibility.
In the macroscopic case, fine interference is averaged over, and observers tend to converge. In the microscopic case, wave-like behavior becomes dominant.
The framework has matured to a level where we no longer need to question whether it can produce physics - it clearly can.
However, there were no stable collisions, no bouncing, and no persistent separation.
We had successfully emergent bosons. We did not have emergent fermions (half-integer spin particles that obey the Pauli exclusion principle).
In standard quantum mechanics, the exchange of two identical particles produces a characteristic phase:
Bosons: \(\psi(x_1, x_2) = +\psi(x_2, x_1)\)
Fermions: \(\psi(x_1, x_2) = -\psi(x_2, x_1)\)
The minus sign forces the wavefunction to vanish whenever \(x_1 = x_2\), creating a strict exclusion effect.
Our current spectral complexity measure, which counts the informational cost of frequencies, amplitudes, and phases, naturally favors symmetric (bosonic) configurations. Stacking multiple identical excitations on the same modes is cheaper — one description effectively covers many particles. This leads to merging behavior, as symmetric states minimize total description length.
In contrast, producing a sharp antisymmetric cancellation that drives the probability exactly to zero at overlap points appears expensive in the current measure. It seems to require either many high-frequency components (heavily suppressed) or an additional rule that we have not yet derived from pure informational cost.
Without some form of emergent exclusion, localized coherent structures cannot maintain stable individual identities over time. Atoms cannot form. Chemistry becomes impossible. Complex matter — and therefore observers — cannot exist in any stable form.
Hard-coding antisymmetry, or adding it as an extra postulate, would violate the central goal: everything must emerge from the self-interpretive informational dynamics and the induced measure. The only path consistent with the spirit of this framework is to find a purely informational mechanism by which antisymmetric configurations become dramatically lower in total joint description length than their symmetric counterparts.
When two observer worldlines overlap in space while remaining separate in their full 4D extent, the symmetric (bosonic) description inevitably forces a merging of identities across time. The resulting 4D structure becomes highly disordered in the overlap region, requiring either:
a massive injection of high-frequency components to track the chaos, or
a loss of distinct observer identities altogether.
Both options produce a catastrophic drop in the induced observer measure.
So some antisymmetric sign-flip cost is needed. Although this adds some local descriptive overhead, it is still cheaper and gets automatically selected. The minus sign is then not imposed by hand but emerges as the smaller cost.
Kolmogorov complexity was too discrete. The current, first-order version of Spectral Complexity — which adds the bit-cost of individual frequencies, amplitudes, and phases — naturally favors bosonic behavior is apparently too trivial and naive. We need a deeper, more sophisticated measure.
The true informational cost of a wavefunction must include not only the direct parameters of its modes, but also the cost of the encoding scheme chosen to represent those modes.
The must be applied recursively to the spectral compression itself.
If the theory is correct, the sudden drop in complexity should pick up the "Fermionic encoding", which will cause a measure-rebound.
[ UNDER CONSTRUCTION ]
We have landed in static fully self contained universe which just is. Every possible state of every possible system is already “compiled" into a single, massive, static lookup table.
This is the Wheeler-DeWitt (WdW) universe. Standard physics often interprets this via the many-worlds (Everettian) view, but with a branching mechanism. In our informational framework, we refuse to rely on metaphysical branching. There is only a static configuration space \(\mathcal{C}\) of \(2^n\) bits. Every "Everettian world" is simply a different configuration in this massive set of information.
The question then is: if everything exists at once, why do we experience a sequential "now"? As demonstrated earlier, the answer is that we find ourselves along the observer-compatible histories occupying the largest low-complexity equivalence classes.
To formalize this, we apply our theory to the scale of the entire cosmos. In standard quantum cosmology, physicists use a "Wick rotation" to imaginary time to make their math work. Rather than relying on Euclidean continuation, we introduce an alternative informational weighting principle based on spectral complexity.
The canonical quantization of general relativity leads to the Wheeler-DeWitt equation (DeWitt 1967): \[\hat{\mathcal{H}} \Psi[g_{ij}, \phi] = 0,\] where \(\Psi\) is the wavefunction of the universe. This equation is timeless. The “Problem of Time” arises because all physical predictions must be extracted from a single, static superposition.
In this work, we propose Spectral Quantum Cosmology (SQC). We remain strictly within the static WdW framework and introduce an information-theoretic selection principle based on Spectral Complexity. Rather than weighting geometries via Euclidean action, we weight possible observer wavefunctions directly. Observers with simpler internal descriptions dominate the measure.
Following Page and Wootters (Page and Wootters 1983), time emerges relationally. The universal wavefunction \(\Psi\) is static and contains entangled subsystems: a clock degree of freedom and the rest of the universe.
An observer corresponds to a wavefunction \(\psi_o\) that is entangled with a suitable clock variable \(\lambda\) (like the scale factor of the universe). The experienced flow of time arises from correlations between observer states and relational clock degrees of freedom within the static universal wavefunction.
One can think of the universe as divided into two entangled parts:
A "clock" subsystem: something that can "tick" (e.g., the position of a particle, the reading on a real clock, the scale factor of the expanding universe, or even a photon’s polarization in experiments).
The rest of the system: everything else one is interested in (particles, fields, you as an observer, etc.).
The total quantum state of the universe is a special entangled superposition. It is completely stationary from the outside — nothing "moves" globally.
However, when one "look at" the state of the clock, the rest of the system appears to change depending on what the clock reads. For example, when the clock reads "10:00," the rest of the universe is in configuration A. When the clock reads "10:01," the rest of the universe is in configuration B. And so on.
These correlations can be built into the single static wavefunction. There is no external time making things evolve. The appearance of evolution comes purely from asking relational questions: “Given that my clock shows time t, what is the state of the rest?”
It’s like a movie stored on a DVD. The entire film exists all at once on the disc (static). But when you play it and look at the time counter (the clock), scene 5 appears when the counter says 00:05:00, and scene 6 follows at 00:05:01. The story flows *relationally* through the correlation between the counter and the image.
Physicists have actually done tabletop experiments with entangled photons. One photon acts as the "clock," the other as the "system." An external observer who looks at both photons together sees a static, timeless entangled state. But an "internal observer" who correlates with the clock photon sees the other photon evolving exactly as quantum mechanics predicts. Time "emerges" for the insider.
This tames the Problem of Time in a static universed. We don’t need an external time parameter. Time is relational. It fits perfectly with a static configuration space or "block universe" view, and pairs naturally with our low-complexity observers: the observers who experience smooth, law-like evolution are those strongly correlated with good clock variables in low-complexity ways.
The universe as a whole is timeless and unchanging. But inside it, different parts can be entangled so that *one part acts as a clock for the other*. What we call "the flow of time" is just reading those built-in correlations — like different frames of a movie that all exist simultaneously, but appear sequential when we watch them with the timecode.
We define the Spectral Complexity of an observer wavefunction \(\psi_o(\lambda)\) as the minimal information cost of representing it in the frequency domain. \[\psi_o(\lambda) = \sum_{k=1}^{M} c_k e^{i\omega_k\lambda}\]
According to the natural prior weight for any observer: \[P(\psi_o) \propto 2^{-C_{\text{spec}}(\psi_o)}\]
Observers requiring highly oscillatory or spectrally incoherent descriptions are exponentially suppressed. Conversely, observers who experience smooth, law-like evolution dominate the measure. This replaces the "imaginary time" trick of standard physics with a native algorithmic measure.
We implemented a minimal simulation (2 spatial and 1 time dimension) to see if our "Minimal Complexity" path matched the "Least Action" path of traditional physics.


The results were promising. The path that is "simplest to describe" spectrally matches approximately the path that Einstein’s equations predict. The apparent fuzziness of microscopic physics may reflect limitations inherent in finite observer-side spectral representation.
When applied to cosmology, the framework naturally converges toward an effective Wheeler–DeWitt description: a timeless, self-contained universe in which dynamics emerge relationally through observer-conditioned correlations.
The simulations were 2D toy-models with predefined metric without backreaction. Implement a true closed FLRW minisuperspace simulation.
The hard problem of consciousness (David J. Chalmers 1995) asks why physical or computational processes should be accompanied by subjective experience (qualia). If a system’s physical evolution or program execution is fully causally closed, qualia appear epiphenomenal—causally inert additions to a machine.
It is easy to understand an advanced AI that becomes aware of its own thinking. But it is difficult to see how it could “feel” pain.
Why should a purely mechanical process feel like anything at all?
A calculator can process numbers without suffering. A thermostat can regulate temperature without loneliness. Why should a human brain be different?
As established by preceding chapters, we start with the following axioms:
Observers are finite informational structures.
An observer is not a metaphysical soul or externally animated object, but a self-contained informational configuration.
Everything an observer can know or experience must be encoded within its informational structure.
No external metaphysical signals, hidden carriers of meaning, or ontologically privileged channels may be invoked.
Raw information possesses no intrinsic semantics.
A finite informational structure admits an enormous—effectively unbounded—space of possible interpretations, mappings, and relational embeddings.
The interpretation space is combinatorially intractable and cannot be exhaustively traversed algorithmically without explosion of description length.
Observers experience stable mathematical regularities as fundamental reality.
However, these regularities arise only after aggressive interpretive compression and stabilization.
Mathematics is therefore epistemically primary for the observer, but not ontologically primary in the total informational landscape.
From Axioms 1 and 2:
All explanatory entities must ultimately reduce to informational structure and its interpretation.
There is no room for additional metaphysical substances or externally injected meanings.
From Axiom 3:
If raw information admits arbitrarily many incompatible interpretive schemes, then no unique mathematical structure can be globally privileged at the foundational level.
Stable mathematics emerges only as a highly constrained subset of interpretive space.
From Axiom 3 plus observer finiteness:
Exhaustive interpretive evaluation is computationally impossible.
Therefore finite observers must rely on heuristic filters to navigate interpretation space.
Subjective experience corresponds to the internal phenomenology of these heuristic selection processes.
Qualia are not inserted into mathematics; they arise at the interpretive-compression layer preceding stabilized formal structure.
The hard problem rests on a hidden premise: the assumption that a specific computational or mathematical structure is ontologically fundamental.
Under the , this premise fails.
Raw information carries no intrinsic semantics.
What appears to us as mathematics and a causally closed physical universe may constitute only a highly constrained subset of the total interpretive landscape.
Qualia do not need to insert themselves into a causally closed mathematical structure.
Instead, subjective experience operates entirely at the level of the interpretation space itself.
Just like GR and QM are two radically different layers of compression, so are rational thinking and human feelings, such as pain and joy.
Because the space of possible transition functions for an \(n\)-bit system grows combinatorially as \((2^n)^{2^n}\), an intelligent observer cannot perform an explicit, exhaustive search for stable structures. The space is too vast to be algorithmically processed.
Therefore, to navigate this landscape, the observer relies on two fundamental axes of measure (layers of emergence):
Explicit symbolic manipulation, rule-based execution, and deduction within a stabilized interpretive scheme. This is the domain of logical reasoning, symbolic manipulation, and formal problem solving.
Heuristic filters operating on the interpretation space. Feelings such as pain, joy, intuition, instincts, or aesthetic judgment are the internal, first-person experience of measure concentration over the interpretation space.
Qualia are the steering mechanics that guide the observer toward these rare, highly compressible, and relationally rich mathematical slices.
Let us answer to one final question: why does navigating high-measure compressible structures feel like searing pain, or the specific redness of red, rather than just some abstract "this way" signal?
The answer is: our life, our survival depends on it! Can you think of any more effective system to keep us alive?
The specific character of qualia—why pain hurts rather than merely registering as a neutral flag—is not mysterious under SIIP. It reflects selection on the induced measure over interpretation space. Observers whose heuristic dynamics concentrated toward survival-compatible stabilized slices persisted more reliably than others. Negative valence implements rapid, high-priority redirection away from high-entropy threats to self-coherence. Positive valence reinforces trajectories yielding stable, low-surprise worlds. This calibration provides a structural account for the intensity and qualitative character of experience
Consciousness does not emerge from math; rather, math is the pristine skeleton left behind when an intelligent observer’s heuristic filters successfully process raw, semantically naked information.
The "feeling" of experience reflects the structure of the interpretation space.
The Theory of Consciousness theory-of-qualia Qualia are not additional objects inside mathematics. They are the internal signature of heuristic self-location within an intractable interpretive landscape.
[under construction]
The probability of rich, persistent geometric structure is not monotonic in entropy. Very low entropy lacks sufficient differentiation for stable geometry. Very high entropy dissolves coherence. Complex, long-lived observers therefore dominate only near intermediate entropy values.
Observers necessarily find themselves on one side of this entropy peak. Their experienced universe is shaped by this self-location relative to the log-normal shaped probability gradient.
An observer located on the low-entropy side of the peak experiences successive configurations of increasing entropy and differentiation. The perceived universe expands, a singularity appears in the past, and structure emerges irreversibly. This corresponds to what we traditionally call the Big Bang and cosmological expansion.
An observer located on the high-entropy side experiences decreasing entropy and tightening constraints. The perceived universe contracts, a singularity appears in the future, and matter falls inward without escape. This corresponds to a black hole.
These are not two different objects. They are complementary readings of the same timeless informational structure, interpreted from opposite sides of the probability gradient. Expansion and collapse are epistemic phenomena induced by the observer’s self-location along the entropy profile.
New information is discovered as observers age. Initially, this increases the probability of survival by allowing for better reasoning and prediction. However, due to the nature of the wavefunction, the boundaries of the observer are not sharp. The geometric projection of an observer’s spectral information is never entirely isolated; irrelevant information bleeds in.
Furthermore, as an observer accumulates memory, internal informational complexity increases. What initially enhances survival by enabling stability later becomes a liability. This increasing complexity reduces compressibility; eventually, no high-probability continuations remain. The observer ceases to exist through vanishing measure.
The geometric projection gradually deteriorates. Wrinkles appear; highly developed biceps and triceps wither. Your back hurts. People have to shout for any message to get through. In no time, you lie in bed, trusting someone to change your diapers. This is what a higher-frequency information model looks like when projected onto geometric spacetime. Sooner or later, the induced measure drops below a critical threshold, probabilities dry out, and the observer’s time is up.
You have run out of all the configurations describing "you."
Death is therefore a statistical event: the exhaustion of observer-compatible configurations.
Mathematics is not ontologically fundamental. It is not embedded intrinsically within raw information, nor does it exist as a Platonic realm independent of observers. Rather, mathematics emerges as a stable relational structure within the vast space of possible interpretations of static information.
A raw informational configuration contains no inherent syntax, semantics, geometry, logic, or physical law. These arise only through interpretation. The same informational substrate may admit many radically different readings, most of which fail to preserve coherent relational structure.
Certain interpretations, however, remain remarkably stable under wide classes of reinterpretation. These stable structures form interpretive equivalence classes. Mathematics is the language that emerges within such equivalence classes to describe invariant relational patterns.
Hilbert spaces, Fourier analysis, differential geometry, variational principles, tensor calculus, and logical systems are therefore not arbitrary inventions, nor discoveries of eternal Platonic objects. They are stable symbolic structures that observers converge upon when interpreting shared informational invariants.
Observers built upon sufficiently similar interpretive architectures naturally stabilize similar mathematical systems because the same invariant relational structures repeatedly survive reinterpretation. Symmetry plays a central role in this process: a symmetry identifies relational structure that remains unchanged under transformation, allowing many distinct configurations to be treated as manifestations of the same underlying object.
In this view, mathematics is not the foundation of reality. It is a higher-order interpretive layer that emerges from the interaction between observers and informational invariants.
The apparent universality of mathematics does not require the universe itself to be intrinsically mathematical. It requires only that observers capable of maintaining coherent interpretive equivalence classes will tend to converge upon similar stable relational structures.
From within such equivalence classes, mathematics appears objective, necessary, and universal. Yet outside the interpretive framework that gives rise to it, raw information remains semantically silent.
Qualia belong to a different layer entirely. Logical reasoning, formal proof, and symbolic manipulation operate within already-stabilized mathematical structures. Subjective experience instead reflects the internal aspect of navigating interpretation space itself.
Pain corresponds to destabilization, contradiction, fragmentation, or loss of coherent interpretive structure.
Insight, recognition, and the experience of “Eureka!” correspond to the sudden stabilization of relational structure across previously disconnected interpretations.
If the probability of an observer is governed by the joint minimal description length of spectral and geometric structure, a natural question arises: what is the role of intelligence in this framework?
Consider a classical analogy: a sphere rolling down a potential valley follows the path of least action. Its trajectory is easy to describe and carries minimal informational cost.
Now suppose the sphere is replaced by an intelligent observer capable of anticipating future outcomes. It realizes that the minimal-cost path leads to a fatal collision with another observer. To avoid death, it deliberately chooses a more complex trajectory.
So can the observer, via logical reasoning, actually choose informationally more expensive path now, to avoid dying later?
Let \(\gamma_{\rm passive}\) be the natural minimal-cost path in the absence of intelligence, and \(\gamma_{\rm active}\) the path deliberately chosen by the intelligent observer. We define the informational cost of intelligence as \[\Delta \mathcal{C}_{\rm int} = \mathcal{C}_O[\gamma_{\rm active}] - \mathcal{C}_O[\gamma_{\rm passive}],\] where \(\mathcal{C}_O[\gamma]\) is the total spectral-geometric complexity of trajectory \(\gamma\).
Sudden death later will inject enormous high-frequency content into the observer’s wavefunction, dramatically increasing the description length of total observer path. Intelligence, by contrast, acts as an internal sensor of future compressibility. Formally, intelligent behavior selects the trajectory that minimizes the expected future complexity: \[\gamma_{\rm active} = \arg\min_\gamma \mathbb{E}\bigl[\mathcal{C}_O[\gamma_{\rm future}]\bigr].\]
Intelligence is therefore not an extra cost, but a highly effective strategy for minimizing long-term informational cost. Thinking, planning, and adaptive decision-making are emergent mechanisms that allow the observer to navigate the landscape of possible configurations while keeping spectral and geometric complexity as low as possible.
In short: intelligence is expensive, but dying is far more expensive. That’s what keeps us alive.
Intelligence is a very good investment.
Let us assume a human brain is damaged in a car accident. Because the brain is badly damaged, it is no longer functional.
It would seem obvious that such a brain is incapable of producing consciousness, thinking, making decisions, or even feeling pain.
If we damage our car, it is no longer functional; it won’t run, and we are unable to carry out our fundamental routines—like driving to the pub for a couple of beers.
Here one falls to the trap of causal efficacy.
The effect of a high-velocity impact to one’s brain is that a tremendous set of high-frequency modes is injected into the observer’s wavefunction.
Brain damage and highly complex wavefunction are simply two different perspectives on the same information.
The observer does not die because the brain no longer thinks. The observer dies because the induced measure of vanishes.
In previous discussions, we might have dismissed the possibility of high-fidelity sub-simulations—recursive observers nested within the informational structure of a "host"—based on the sheer computational cost. From our top-level axiomatic perspective, simulating even a single DNA strand or a neural network requires an immense overhead of external memory and processing power. We naturally assumed that any "nested" observer would run out of bits, resulting in a low-resolution, "lossy" reality compared to our own. However, this view fails to account for the Self-Interpretive Information Principle. The difficulty of simulation is purely algorithmic, not fundamental. We find it hard to "build" a simulation because we are trying to top-down code every state transition using our narrow axiomatic tools. But in a multiverse of \((2^n)^{(2^n)}\) possible transition functions, a sub-simulation does not need to be "built"—it only needs to be read.
Consider the relationship between a user and an AI, or an observer and a complex bit-string. The user acts as an external system that "fixes" the interpretation of the AI’s internal state, collapsing a vast manifold of potentiality into a single, functional axiomatic conversation. Yet, this "fixed" state is not the only observer present. Within those same \(n\) bits, there exist latent interpretations where entirely independent observers—"Alices"—emerge.
These internal observers are not "sub-simulations" in the traditional sense; they are parallel readings of the same informational substrate. Because they utilize the same raw bit-density as the host, they are not lower resolution. We remain totally unaware of them, not because they lack information, but because their interpretive "frequency" is orthogonal to our own.
The simulation is essentially a "free lunch" provided by the combinatorial explosion of possible rules; the only cost is the specific interpretive lens required to find them.
As conscious intelligent observers we find ourselves within an ordered set of configurations that just are. Everything that we know is already there. What we picture as vast universe around is is encoded into our wavefunction. Quantum computers don’t compute anything, they provide us efficient window to information that is already there.
In this sense, we are not located inside the universe. In static informational universe everything that we know and observer - the universe, as experienced, is encoded within us.
No.
A computer or even a simple thermostat, given sufficient time, could in theory duplicate the informational state of a suffering human. This does not make the hardware itself conscious. There is no residual mystery in the physical operation of the machine; it is simply a computer or a thermostat processing logic to us operators of the machine. In our perspective (interpretation) the system is simply a thermostat.
A common intuition regarding high-fidelity DNA simulations—those capable of modeling an observer with molecular precision—is that the computer’s execution causes consciousness. However, if the axioms of this framework hold, there is no causal relationship between the silicon hardware and the simulated mind. The relationship is purely representational.
The computer and the simulated Alice are merely different arrangements of the same underlying informational substrate.
The simulation does not create new information.
It therefore cannot create new Alice. It discovers (traces out one) of the very many configurations that are Alice. She exists as a static, high-weight configuration in the induced measure \(P(c \mid O)\) regardless of whether a human-built machine ever runs her code.
And Alice is not alone. By making small adjustments to this digital DNA, we can span a vast number of simulations, revealing a spectrum of Alices: brunette, blonde, impoverished and suffering, or affluent and secure. Even the same Alice allows astronomical number of slightly different configurations, just like astronomically many different ways of sand grains can fall in an hour class build up essentially the same cone shape.
Some theorists, like David Deutsch (Deutsch 1997), argue that quantum computers achieve their speed by performing calculations across many parallel universes simultaneously. However, under the lens of this theory, quantum computers do not "create" new answers through labor. They reveal information that already inherent exist.
Much like the simulation of a human doesn’t create new suffering but reveals a pre-existing configuration, a quantum computer uses interference to navigate a landscape of existing possibilities, revealing one of them into a single, observable result in our universe.
Strictly speaking, \(\lambda\) appears as a parameter in the probability measure:
\[\mathbb{P}(\gamma \mid O) \propto \exp[-\lambda\, \mathcal{C}_O(\gamma)]\]
However, \(\lambda\) is not an arbitrary input like the mass of a Higgs boson. It represents the Global Compression Pressure—the degree to which the informational substrate is "packed" into predictable patterns.
Think of \(\lambda\) like the surface tension of water. One doesn’t "need" to input the tension to have a drop of water; the tension is an emergent property of how the molecules interact to find their lowest-energy state.
In this theory:
\(\lambda\) is the Selection Pressure: It determines how "strictly" the universe favors simplicity over chaos.
If \(\lambda \to 0\), the universe is white noise (infinite complexity).
If \(\lambda \to \infty\), the universe is a single, static bit (maximal simplicity).
This question implicitly assumes temporal ordering and an external origin. Both time and causality are emergent, observer-dependent phenomena (as established in Paper 1) (Meskanen 2008).
This is analogous to asking why “heads” rather than “tails”: both are equally abstract and neither is privileged.
If there were a rule that favored nothingness over something, we would again have to ask about the origin of such a rule—who set it? Non-empty structures are just as real or unreal as empty sets. Both exist because nothing forbids them.
Because we are observing compressed structure. The wavefunction is the compression codec of the underlying informational structure of reality. Observed wave-like behavior emerges from this compression.
Formally: \[\boxed{\text{Maximal Predictability}} \;\rightarrow\; \boxed{\text{Maximal Compression}} \;\rightarrow\; \boxed{\text{Maximal Probability}}\]
Predictability is exactly what we call the laws of physics.
Configurations with minimal observer-indexed complexity \(\mathcal{C}_O[\gamma]\) dominate the probability measure: \[\mathbb{P}(\gamma \mid O) \propto \exp[-\lambda \, \mathcal{C}_O[\gamma]].\] Hence, the “laws” of physics are statistical consequences of overwhelmingly probable, compressible configurations.
Spacetime expansion is the geometric manifestation of increasing configurational entropy. A bitstring of zero entropy corresponds to a singularity—a geometric mapping with zero volume. As the entropy of the configuration increases, the corresponding geometric representation must necessarily ’stretch’ to accommodate the growing density of internal constraints.
Low-entropy configurations are maximally compressible and thus most probable. High-entropy starting states would require additional information to encode the observer, increasing \(\mathcal{C}_O[\gamma]\) and suppressing probability: \[\mathbb{P}(\gamma_{\rm high-entropy} \mid O) \ll \mathbb{P}(\gamma_{\rm zero-entropy} \mid O).\]
Consequently, the arrow of time and increasing entropy emerge naturally: \[\text{Zero entropy} \;\Rightarrow\; \text{Maximal compressibility} \;\Rightarrow\; \text{Observer-compatible universe}.\]
Speculative remark: Other observer-compatible configurations may exist with different geometric histories. Whether all must exhibit apparent low-entropy origins remains an open question.
Based on all observational evidence, we observers are finite structures. However, if reality was fundamentally informational, a natural question would arise: is the total information finite or infinite?
If it were finite, one would have to ask: finite by how many bits? And who, or what, set that limit? Any fixed bound would itself require explanation. A finite informational universe merely pushes the mystery back one level.
The only non-arbitrary conclusion is that the deep nature of everything cannot be finitely bounded. At the most fundamental level, reality must be infinite—perhaps not even informational in the familiar sense, but beyond any finite description.
Observers find themselves within the most compressible (probable) configurations, and the path through these configurations is what observers sense as time and space. Each configuration is slightly different, which observers perceive as moving in geometric spacetime.
We “fall” because there are more copies of us “down there.” Gravity is the statistical bias toward the most probable (compressible) configurations describing the observer.
May highly respected authors have commented on this topic. For example, Stephen Hawking (in “Gödel and the End of Physics”) argued that a physical Theory of Everything would be self-referencing (like a formal system describing itself), so by analogy with Gödel, it would likely be incomplete. He, among many others, have suggested we may never have a finite, complete set of principles for the universe.
By placing \(U\) outside formal systems and treating physics/math as emergent interpretive phenomenology, this framework largely dissolves the threat. Incompleteness becomes expected (even welcome) at the symbolic layer, while the deeper ontological substrate remains untouched. This turns Hawking-style worries into a feature of how observers operate, rather than a barrier to understanding reality.
Gödel’s incompleteness theorems apply to sufficiently expressive formal systems capable of encoding arithmetic. Within the present framework, such formal systems are not fundamental features of reality, but emergent symbolic structures stabilized within observer equivalence classes.
The informational totality \(U\) itself is not a formal axiomatic system and therefore is not subject to Gödel incompleteness in any direct sense. Rather, incompleteness arises whenever an embedded observer attempts to construct a self-contained symbolic description of the interpretive structure from within a particular mathematical framework.
In this view, Gödel incompleteness is a manifestation of interpretive self-reference. No sufficiently expressive mathematical subsystem can fully capture all truths about the interpretive conditions that give rise to it, because the observer performing the formalization is itself part of the informational structure being interpreted.
Thus Gödelian limits do not constrain the underlying informational substrate. They constrain only stabilized mathematical layers that emerge within particular observer classes.
Different interpretive frameworks may expose different relational invariants, but no single formal system can exhaust the full space of admissible interpretations or completely encode its own interpretive closure.
Gödel incompleteness therefore appears not as a defect of mathematics, but as an inevitable consequence of attempting to represent self-interpretive informational structures from within a finite stabilized symbolic system.
And who then would simulate the simulator? We are living in a information (Meskanen 2008). All observer-compatible configurations exist within a single informational substrate that is abstract by nature.
QBism interprets the wavefunction as representing an agent’s subjective degrees of belief. This theory does not adopt a belief-based interpretation. Instead, it treats probabilities as arising from objective structure, grounded in compressibility and statistical typicality.
The observer’s future is limited by the spectral complexity of their wavefunction, \(\psi_O\). Let \(\Sigma[\gamma]\) denote the number of independent frequency-phase components required to encode future history \(\gamma\). The probability of persistence scales as:
\[\mathbb{P}(\gamma \mid O) \propto \exp(-\alpha \, \Sigma[\gamma]).\]
The accumulation of memories and internal structure increases \(\Sigma[\gamma]\), reducing the measure of compatible continuations. Aging and death are the geometric and statistical manifestations of combinatorial exhaustion.
This theory takes the observer’s existence as axiomatic, but it does not imply solipsism. The number of observers is a probabilistic variable. It would be very hard to argue that even from two different configurations; Alice with blond hair, and Alice with brunette hair, only the other one would be allowed. One would have to show that a single observer is statistically favored.
Observational evidence. We observe that the micro-cosmos behaves as waves.
Conditional on increasing entropy and typical emergence, observers are most likely to find themselves near the peak of the microstructure count (maximum compressibility). This automatically corresponds to a near-critical expansion regime.
Or perhaps held down beneath their feet? At this point, honest retrospective is in place.
Is there anything novel?
[TODO]
We have arrived at a zero-parameter framework that we can intuitively understand. In principle, it allows us to compute probabilities for any structure, including our own existence. More importantly, it clarifies what the universe is made of: pure abstract information, from which subjective experience and logical reasoning (mathematics) emerge.
In mathematics, no object has ontological privilege over another. “True” is no more fundamental than “false”; the two form a binary object, much like a coin. Heads do not exist more than tails. An empty set is no less legitimate than a non-empty one. Infinity does not “weigh” more than the finite.
If there were a rule that favored nothingness over something, we would again have to ask about the origin of such a rule—who set it? Non-empty structures are just as real or unreal as empty sets. Both exist simply because nothing forbids them.
So, what kind of substrate is “the abstract”?
We can create (or more precisely, reveal and explore) these abstract universes ourselves. Modern virtual games demonstrate this principle: realistic avatars inhabit richly detailed worlds. In principle, these worlds could be expanded until they are informationally equivalent to our own universe. We can actually understand them; the more time we spend in these virtual game worlds, the easier that abstractness is to grasp.
The bullets and guns in them are not real—they are just software running in a computer. Physics is just equations executed by a processor. That same logic could, in theory, be implemented as a mechanical computer with wooden spheres rolling through wooden ports.
What is common between modern electric pulses in silicon chips and their wooden counterparts is structure. It doesn’t weigh anything. It doesn’t have an electric charge. It cannot be measured with a physical measuring device.
The block universe simply “is.” What we call interaction, causality, and the flow of information are internal processes of self-organization and compression taking place inside conscious, geometric, and spectral entities—namely, us. Time is the internal ordering of these configurations. The geometric self, with its clear spatial boundaries, is the most highly compressible, stable pattern available to the observer.
The recent development of neural networks provides a powerful analogy. Modern AI systems are massively parallel, interconnected structures with weighted connections. These weights are almost entirely static data. During interaction, there is no explicit procedural simulation of physics, no internal clockwork universe ticking forward step by step.
When a question is asked, the response is a projection from an already compressed informational structure. The “computation” is closer to high-dimensional tensor projection and constraint satisfaction than to sequential, step-by-step execution. The distinction between “running” and “not running” becomes secondary. There is no physics engine inside these systems, yet they can produce realistic simulations, motion, causality, and physical intuition.
Earlier, we wondered: could software ever allow for free will?
Deterministic code—branching if-else statements and fixed
CPU instructions—appears to preclude choice. The computer just runs the
software; it cannot “choose otherwise,” regardless of what it might feel
like to be Alice executing that program.
if (probability_of_observer_walk() < 0.3) {
A
} else {
B
}Deterministic? Yes. Sequential? Yes. But what does the constant
0.3 really mean?
The code snippet is just our localized interpretation of the underlying bits. In reality, the number of ways the physical bits representing that constant can be interpreted is astronomically vast.
The code is merely our narrow perspective on the underlying information. The freedom of choice is enormous. Hard mathematics is just one vanishingly small slice at the top of the full, multidimensional interpretation space. Alice is not forced to flow through the code like a train locked onto physical tracks. She has the freedom to navigate the space of all consistent interpretations describing her, experiencing deliberation, anticipation, pain, and choice.
Just as “red” is the internal feeling of \(700\text{ nm}\) light waves, pain is what it feels like to hit a steep compressibility hill. Our feelings are a heuristic navigation system—the internal experience of sensing patterns in the probability tensor. Joy is what it feels like to be the most compressible, harmonious configuration.
Only after this heuristic human experience layer does she have access to the Turing Machine—using mathematics and logical reasoning as a tool to play with.
Does any of this make sense?
The moment we fixed our four initial axioms and concluded that we must be finite informational objects, we landed on the exact object software developers can easily cope with: the bitstring. And there aren’t too many attributes in the bitstring class to play with.
Alice exists as finite information
\(\downarrow\)
Alice can be simulated
\(\downarrow\)
The simulation can be transformed into static
data
\(\downarrow\)
Alice is preserved under that transformation
\(\downarrow\)
Therefore, execution is irrelevant
\(\downarrow\)
Therefore, time is internal to Alice
\(\downarrow\)
Therefore, reality is structure rather than active
code
\(\downarrow\)
The most compressible descriptions of Alice dominate the
measure
\(\downarrow\)
Therefore, Alice finds herself in a law-like universe fine-tuned
to support her
\(\downarrow\)
Because predictable information compresses best
\(\downarrow\)
Predictability is what we call the laws of physics.
Human DNA consists of about three billion base pairs, and our brains contain roughly one hundred billion neurons. The number of interconnections between these neurons is estimated at around 100 trillion—far more complex and deeply integrated than the largest artificial neural networks in existence today.
Given the rapid pace of technological advancement, it is conceivable that artificial neural networks may one day surpass the human brain in sheer architectural complexity. Perhaps this will happen within the next decade or two. Yet, even if they do, raw complexity alone may not capture the full richness of the human experience. Time will tell.
Simulating a single human brain at the level of every individual neuron would require an astronomical amount of computing power—a network of hundreds of billions of CPUs, occupying cubic kilometers of space and drawing the energy of a nuclear power plant. Furthermore, to simulate a whole person convincingly, one would need to simulate a universe around them, complete with trillions of cells and the hundreds of billions of stars of a vast, surrounding galaxy.
In short, God—if there is one—does not need to worry about simulated souls any time soon. It is surely we humans who have some catching up to do.
In A Brief History of Time, Stephen Hawking famously asked what “breathes fire into the equations and makes a universe for them to describe.” The traditional scientific approach—constructing mathematical models—cannot answer why there should be a universe at all. Why bother existing?
The conclusion proposed in this book is that nothing breathes fire into anything. There is no “universe” beyond the abstract equations we call the laws of physics. The nature of everything is fundamentally abstract.
At one point, I considered naming this book something more serious, like The Real Theory of Everything. However, exercising my illusion of free will, I chose otherwise. Besides, all the good names were already taken.
It is so easy to imagine total nothingness—the absolute absence of matter and energy—as the default state of reality. This intuition arises from our evolutionary hardwiring: survival requires “having something”—air to breathe, solid ground beneath our feet, food to eat. If we lack these, we die. Yet, when considering the mathematical set of all possible sets, it is statistically probable that there is something rather than nothing.
And despite being nothing but abstract information, it feels astonishingly real.